







在PC上最好的动画观看体验需要复杂的环境配置和硬件支持,本文介绍了这一套方案同时有极佳的上采样和去噪的画质,也有插帧带来流畅的拉镜头效果。如果你曾经只在线观看过动画的,请一定要试试。本文介绍的这一套方案使用MPC-HC播放器[1],madvr滤镜[2],SVP插件[3]和Anime4K着色器[10]。

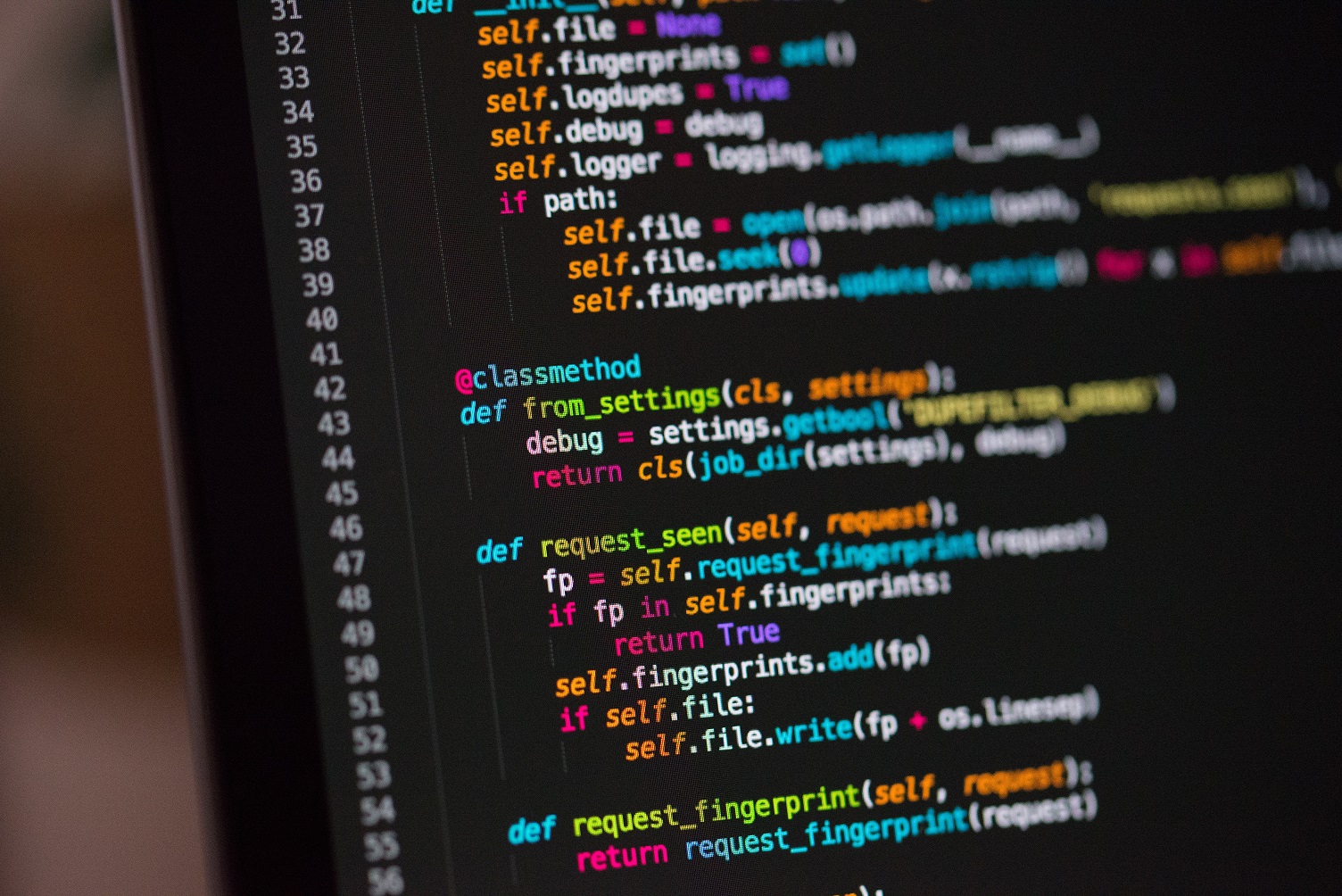
Python编程基础05:Python的过程分解和文件IO
人生苦短,我用Python![1]
这次的主要内容主要是介绍Python中的过程分解和文件IO。过程分解包括了函数(function),模块(module)。而文件IO主要是介绍使用Python打开文件并进行读写操作。

解锁网易云变灰曲目PC版(Windows, MacOS)
作为网易云的9级VIP用户,由于国内音乐版权的问题,用了那么久还订阅会员的网易云看到了很多音乐因版权而下架,于是折腾了一下,使用GitHub上现成的实现给网易云换源,从而解决音乐下架的问题。在这篇文章里,将会分享一下怎么在网易云PC上使用这项技术。
Python编程基础04:Python高级集合类型和一些杂项
人生苦短,我用Python![1]
这个系列是一个帮助零基础的人入门编程的教程,本文承接上一篇,介绍Python的另外两个重要的数据类型(字典dict和集合set)。另外,break, continue, 注释和IO也会在本文的下半部分介绍。

Aria2傻瓜安装部署指南
Aria2是一个非常好用的P2P开源下载工具,不仅支持普通的HTTP链接下载,也可以使用BT种子,磁力链接。在体验过迅雷这样的国产流氓软件之后,有一款实用的下载工具还是很重要的。在这篇文章里,将介绍如何在Linux中安装并且部署运行Aria2和它的可视化界面AriaNg。在家庭局域网的路由器和NAS中,很有可能是基于Linux系统的,所以可以很方便的将Aria2服务部署起来,并且从其他网络位置进行访问。

在UEFI Secure Boot下的Linux安装N卡驱动
最近在帮忙给一台单卡3090的工作站装Linux系统,结果踩了不少坑,折腾了一天多才成功装上。这篇文章就来分享一下,有哪些坑,然后自己是如何解决的。
当然其中最大的原因都是因为这台电脑是组织管理的,自己没有权限设置BIOS,并且强制启动Secure Boot,就算是有win10管理员账号也解决不了任何问题。

计算机视觉中的Transformer
深度学习中最一开始的Transformer是2017年推出的,非常强力[1]。可能当时作者觉得这个东西很强,所以才会赋予”变形金刚”的名字吧。而后来,Transformer也广泛的推广到了计算机视觉(CV)领域,从2020年开始,就有对Transformer在CV中的大量新研究发表。
本文主要会讲最初的Transformer,Vision Transformer(ViT)和Multi-scale Vision Transformer(MViT)。
一些邮箱客户端的使用对比
邮箱在日常中使用非常频繁,基本上一个月要发几十封邮件,所以试了试一些比较有名的客户端看看各方面表现如何。下文中分别以PC客户端和手机客户端分开考虑,分别列出了表格介绍各方面的优缺点,并且总结了自己现在的使用方式。