








异星工厂的品质扩展包给游戏带来了新的生产规划挑战,比起像以前只能横向扩张工厂的规模,现在可以通过使用高品质的工厂和插件,大幅增加产量。为了最大化如传奇品质的高品质物品的生产,我们需要对高品质产率的计算和规划进行一些分析。
比之前更进一步的终极看番工具栈
之前的文章中讨论了如何在Windows上配置最佳的视频播放器用于看番,然而这个方法具有很大的局限性。这篇文章将介绍如何搭建一个更加完善的系统,为了获得真正的快乐终极看番体验。
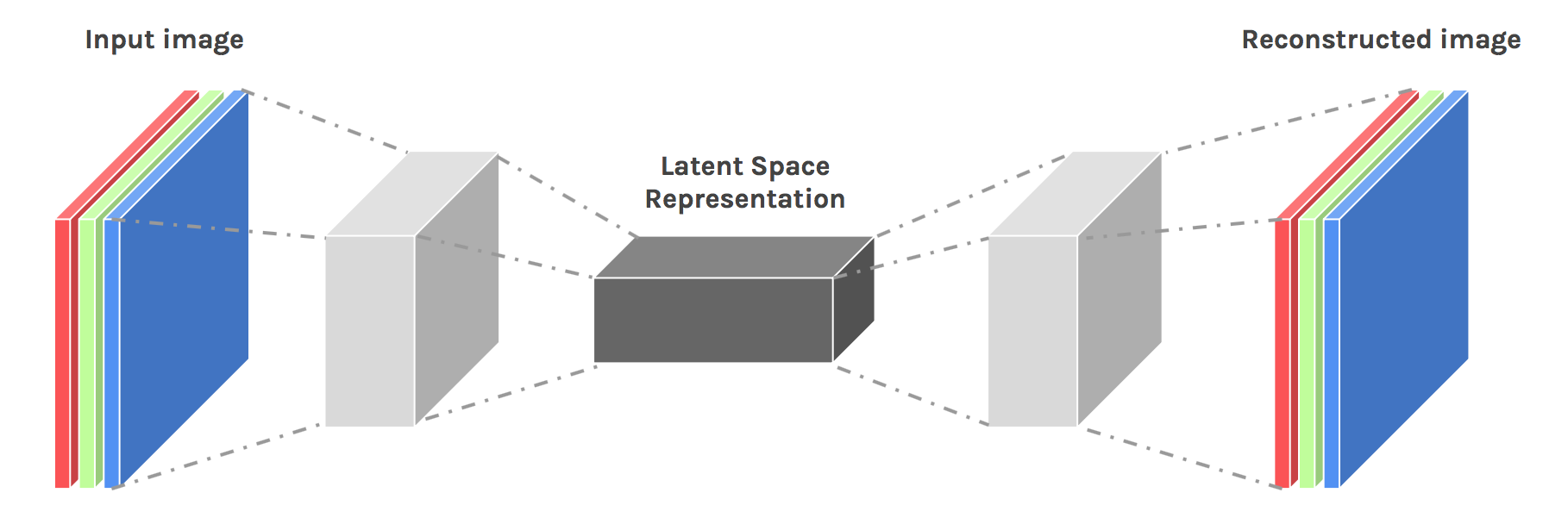
探索数据潜力:预训练模型与Masked Autoencoder的表征学习之旅
表征学习(Representation Learning)是一个深度学习中的概念,通过预训练一个特征提取器,把原始数据转换成有意义的低维特征,让下游任务基于这些特征进行训练,从而降低了对数据和计算能力的需求。本文将介绍表征学习的基本概念,以及以Masked Autoencoder[1]为主的最新进展。
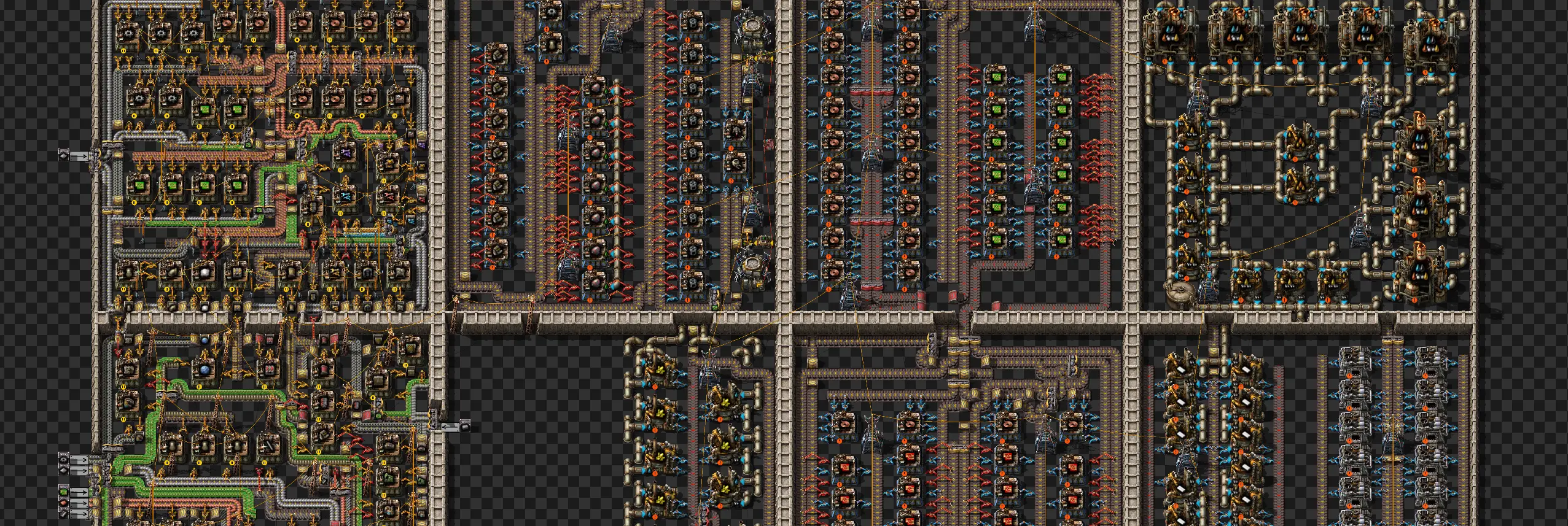
异星工厂原版原创蓝图分享
前一阵子在异星工厂(Factorio)上玩了一段时间,这个游戏的玩法是建造工厂,从最初的手工采矿到自动化采矿,再到自动化生产,最后到自动化科研,最终建造火箭逃离星球。为了下次更好的游戏体验,最近特地的制作了一些用于原版的蓝图,方便下次游戏时直接使用。

学习AI绘画,从Diffusion和CLIP开始
AI绘画在这几个月火了起来,它能从提供的文字和图片中生成新的绘画,质量很高,而且非常有趣。这个封面就是用AI生成的[1]。但是在使用AI绘画的过程中,搞不懂steps,sampler之类的意思。为了想要更好的使用AI绘画,也想要理解AI绘画中那些参数的含义,所以本着学习新技术的目的,写了这篇文章来学习一下AI绘画。

怎么通信比较快?Python跨进程通信测试
在一些场合下,我们需要同时运行多个Python程序,并且希望这些Python进程之间能互相通讯,发送一些值或者接收一些值。本文我们就来测试一下Python的跨进程通信不同方案的效率。
本文包含的内容有:HTTP, websocket, multiprocessing, gRPC, RabbitMQ等。
Python编程基础06:Python的面对对象编程
人生苦短,我用Python![1]
这次我们来学习一下Python的面向对象编程(Object-Oriented Programming),也被简写为OOP。OOP是一种编程思想,可以让程序有更好的扩展性,可读性和可维护性。
1 / 3