







表征学习(Representation Learning)是一个深度学习中的概念,通过预训练一个特征提取器,把原始数据转换成有意义的低维特征,让下游任务基于这些特征进行训练,从而降低了对数据和计算能力的需求。本文将介绍表征学习的基本概念,以及以Masked Autoencoder[1]为主的最新进展。
深度学习的民主化问题
在过去的几年中,深度学习在各个领域取得了显著的成就。然而,深度学习的成功很大程度上依赖于大量的标注数据,而这些数据的获取成本往往很高。例如,对于计算机视觉领域,ImageNet数据集[2]的标注成本高达200万美元。因此,如何利用少量的标注数据来训练一个高性能的模型,是一个很有意义的研究方向。评价一个深度学习模型是否好用的时候,一般会以两个方面进行对比。一个是性能,比如说分类任务的准确度,生成任务中的PSNR,SSIM等。另一方面是运行的效率,包括训练和预测的时间,以及模型的大小。
但是,以GPT-3为例,其参数量高达1750亿,训练时间长达355个GPU年(V100),数据集包含了4990亿个token,花了差不多460万美元[3]。这样的模型对于学术界和初创企业大部分人来说,最多只能通过API访问,不可能通过自己训练和微调来使用。这个就是深度学习的民主化问题,只有少数人能够享受到深度学习带来的好处。因此,如何在保证性能的同时,降低模型的大小和训练时间,是一个很有意义的研究方向。
提取特征
直觉上,通过提取有意义的特征可以降低数据的维度,使模型训练更加容易,包括减少了对数据的需求,也降低了模型的大小。这里列举几个在不同模态下常见的特征提取方法。
视觉
- 在ImageNet[2]上的预训练模型,提取倒数第二层的输出作为特征
- 通过
torchvision库加载预训练模型 model_ft = models.resnet18(pretrained=True)
- 通过
- OpenFace[4]
- 一个基于深度学习的人脸分析开源工具包
- 使用预训练模型提取人脸特征
- 光流(Optical Flow)

Fig. 1. 光流. Adapted from [7]
音频
- 梅尔频谱图
- 表示了音频信号在不同频率下的能量分布
- 通过对音频信号进行傅里叶变换,然后对频谱进行滤波,最后再进行傅里叶逆变换,计算得到的结果
- 把本来是1D的音频信号,转换成了2D的梅尔频谱图
- 梅尔频率倒谱系数(MFCC)
- 从梅尔频谱图中提取的特征
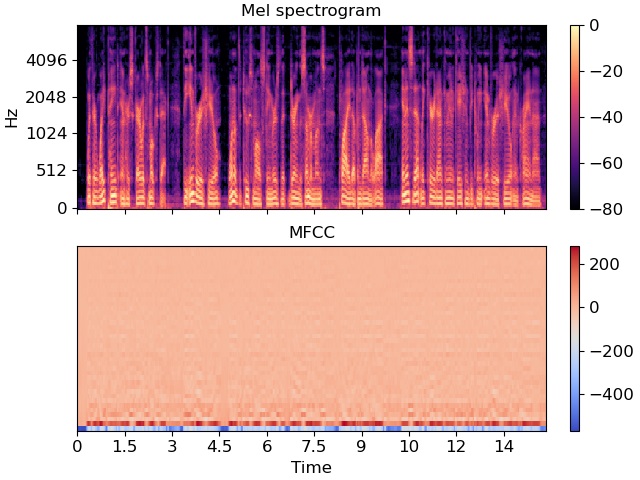
Fig. 2. 梅尔频谱图和MFCC. Adapted from [8]
- DeepSpeech[9]
- 一个用于语音识别的深度学习预训练模型,可以提取音频特征
文本
- TF-IDF
- 通过计算单词在文档中的出现频率,来计算文本特征
- Word2Vec[10]
- 通过预训练一个神经网络,把单词转换成低维的向量
- 如图所示。
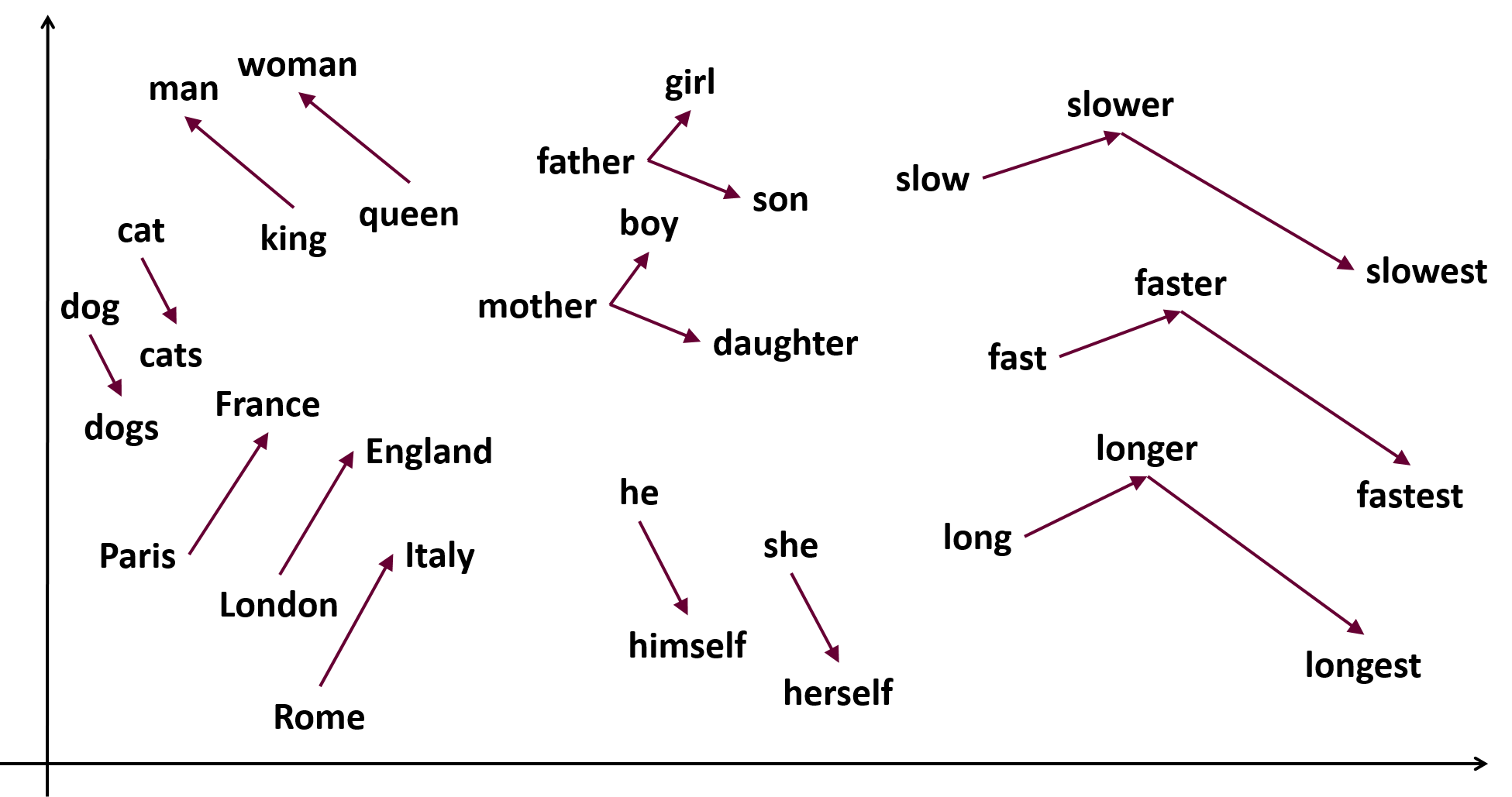
Fig. 3. Word2Vec. Adapted from [10]
- BERT[11]
- 同样也是通过预训练一个神经网络,把单词转换成低维的向量
- 例如,可以使用
transformers库[12]加载预训练模型 model = BertModel.from_pretrained('bert-base-uncased')
表征学习
如果将刚才提到的全部特征类型分个类,那么大致上可以分成两类。
- 一类是通过预训练模型提取的特征,例如ImageNet上的预训练模型,OpenFace,DeepSpeech,BERT等等
- 另一类是通过传统方法提取的特征,例如光流,梅尔频谱图,TF-IDF等等
AI教父Yosha Bengio在第一次ICLR会议上提到
Learning representations of the data that make it easier to extract useful information when building classifiers or other predictors. [13]
那么表征学习的意义就是通过学习数据的表示形式,使得在构建分类器或其他预测器时更容易提取有用信息。换句话说,就是需要想办法获得一个更好的特征提取器。
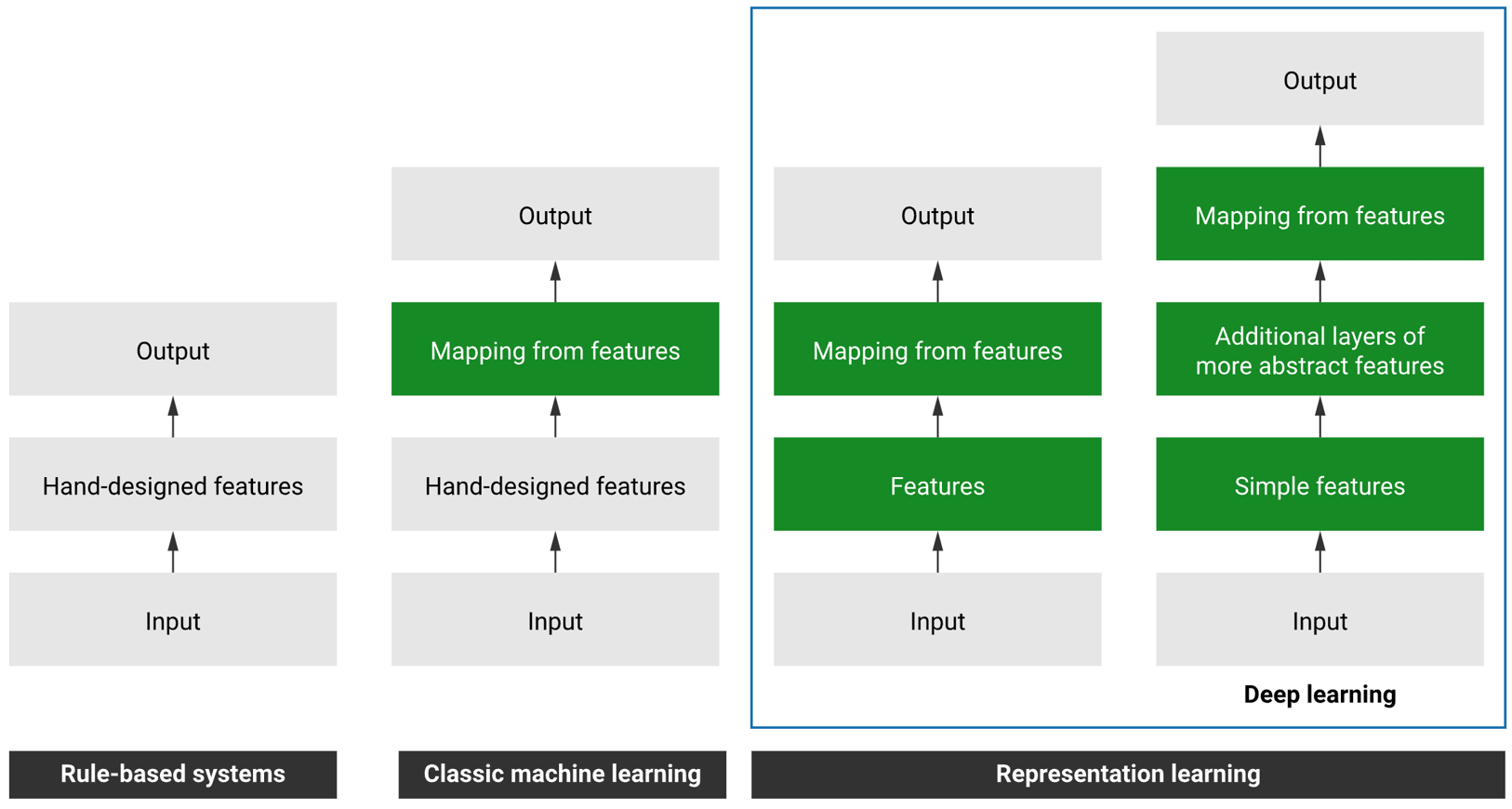
Fig. 4. 智能系统的发展
如上图所示,智能系统的发展经历了四个阶段。
- 第一个是基于规则的系统。
- 开发者通过手动编写代码,来实现系统的功能,比如说分类或者预测等等。
- 第二个是传统的机器学习。
- 开发者需要通过手动提取特征,然后再基于这些特征训练传统的机器学习模型,从特征映射到标签。
- 而第三个和第四个都属于表征学习。
- 开发者通过训练模型,让模型的中间部分学习到数据的表示形式,然后再基于这些表示形式进行预测。
- 而最新的第四个通过加深模型层数,可以让模型学习到更高层次的表示形式,从而提升模型的性能。
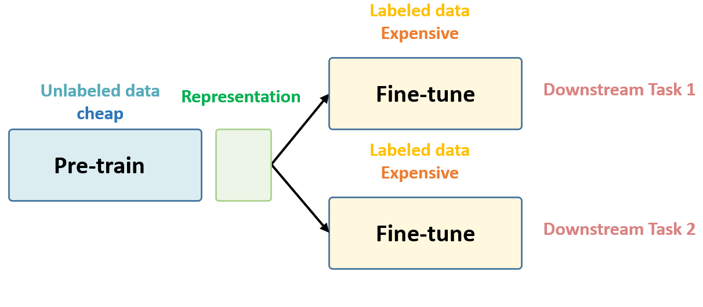
Fig. 5. 表征学习的架构
因为带有标签的数据集很贵很难获得,所以当我们训练模型的时候,一般不会从零开始直接使用有标签的数据集。相反,我们会先使用未标记的数据集,从零开始训练模型参数,将其训练到合理的水平。这一部分,我们称为预训练(pretraining)。
在预训练阶段,使用未标记的数据集从零开始训练模型参数,将其训练到合理的水平。一旦参数训练到了合适的水平,我们就可以使用标记数据集来对模型进行微调,以适应特定的下游任务。在这个阶段,我们不需要大量的标记数据,因为参数已经在第一个阶段训练到了较好的水平。
第一个阶段没有涉及任何具体任务,只是用一堆未标记的数据进行预训练。我们称之为“in a task-agnostic way”。第二个阶段是使用与任务相关的标记数据对模型进行微调。我们称之为“in a task-specific way”。
Masked Autoencoder
在了解了表征学习的概念之后,这里介绍一个领域内较为热门的前沿模型,Masked Autoencoder (MAE)[1]。
介绍
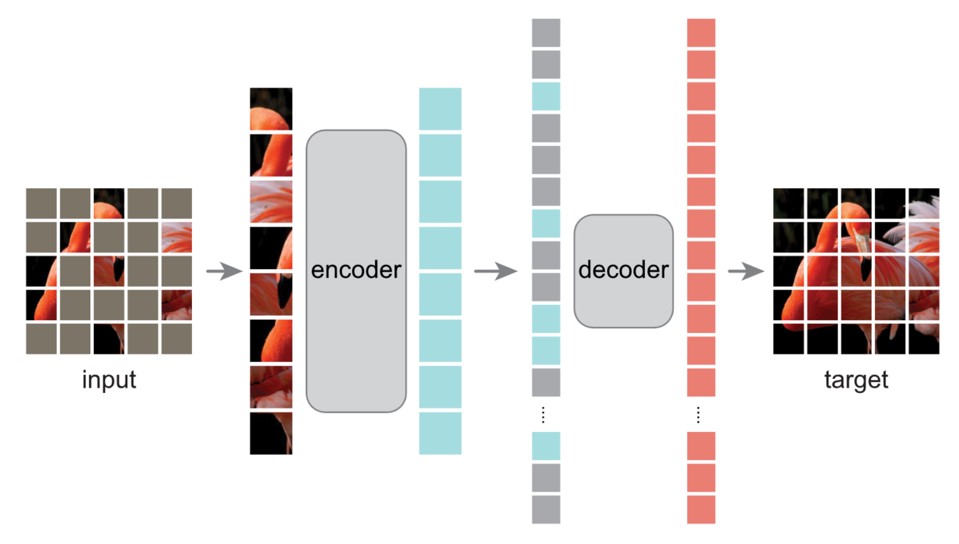
Fig. 6. Masked Autoencoder的介绍. Adapted from [1]
如图所示,MAE主要概念是遮盖输入图像的随机块并进行重建。它基于两个想法。
首先,研究人员提出了一个编码器-解码器架构,其中一个编码器只对图像的可见块子集进行操作。然后,一个简单的解码器可以从可见部分的潜在表示中重构原始图像。
其次,研究人员发现,如果他们遮盖了输入图像的大部分,比如约75%,实际上可以产生重要且有意义的自监督任务。通过结合这两个设计,我们可以高效地训练大型模型,将训练速度提高3倍或更多,同时提高准确性。
一些模型结构上的细节:
- 使用ViT作为编码器,tokenize输入图像并且进行处理成token
- 编码器的结构要大于解码器
- 重建损失在隐藏的token之间进行计算,而不是在所有token之间进行计算
实验结果
在ImageNet上的实验结果如下图所示:
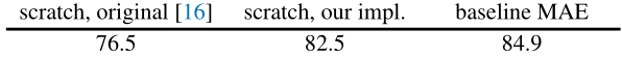
Fig. 7. MAE在ImageNet上的实验结果. Adapted from [1]
其中这里”scratch, original”代表从ViT原论文[14]拿到的结果。
“scratch, our impl”指的是一样的ViT结构,但是使用了作者自己的参数。主要是有更高的weight decay。
“baseline MAE”指的是从预训练的MAE模型开始,进行微调的结果。
这里看到相比于从零开始训练,使用MAE进行预训练,可以提升大约2%的准确率。
为了能更好的选择遮盖的比例,作者进行了一些实验,如下图所示: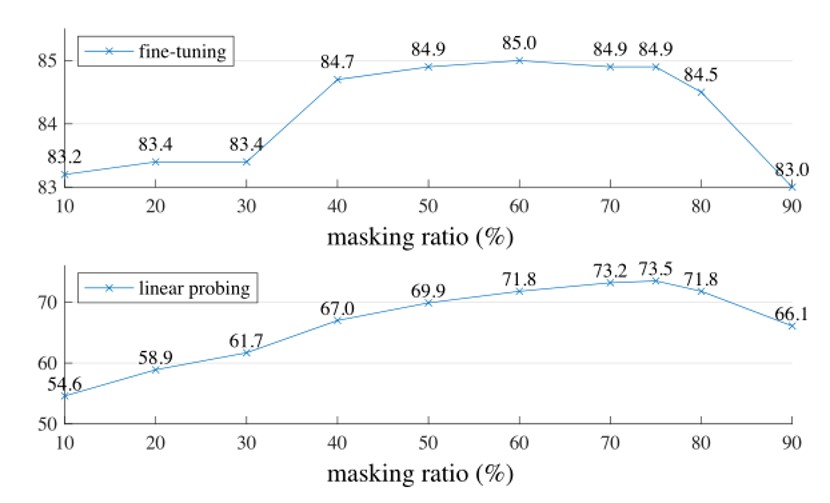
Fig. 8. MAE在不同遮盖比例下的实验结果. Adapted from [1]
上面这张图是在finetune下,也就是同时训练编码器和分类器。而下面这张图是在linear-probing下,也就是只训练分类器。
可以看到,当遮盖比例过高和过低时,都会导致准确率下降。而在75%左右的遮盖比例下,可以达到最好的效果。
除了遮盖的比例之外,怎么选择遮盖的区域也是一个问题。作者进行了一些实验,如下图所示:
Fig. 9. MAE的不同遮盖策略可视化. Adapted from [1]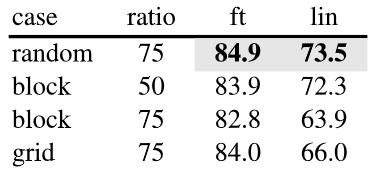
Fig. 10. MAE的不同遮盖策略的实验结果. Adapted from [1]
其中random就是完全随机遮盖,block是选择一个方框区域进行遮盖,grid是有规律的进行网格状覆盖。
从结果可以看出,random是最好的。
扩展到视频
既然MAE可以用在图像上,那么我们能不能将其扩展到视频上呢?答案是肯定的。我们可以将视频看作是一系列的图像,然后使用MAE进行预训练。
去年NeurIPS 2022有个spotlight工作就叫VideoMAE[15],就是将MAE扩展到视频上。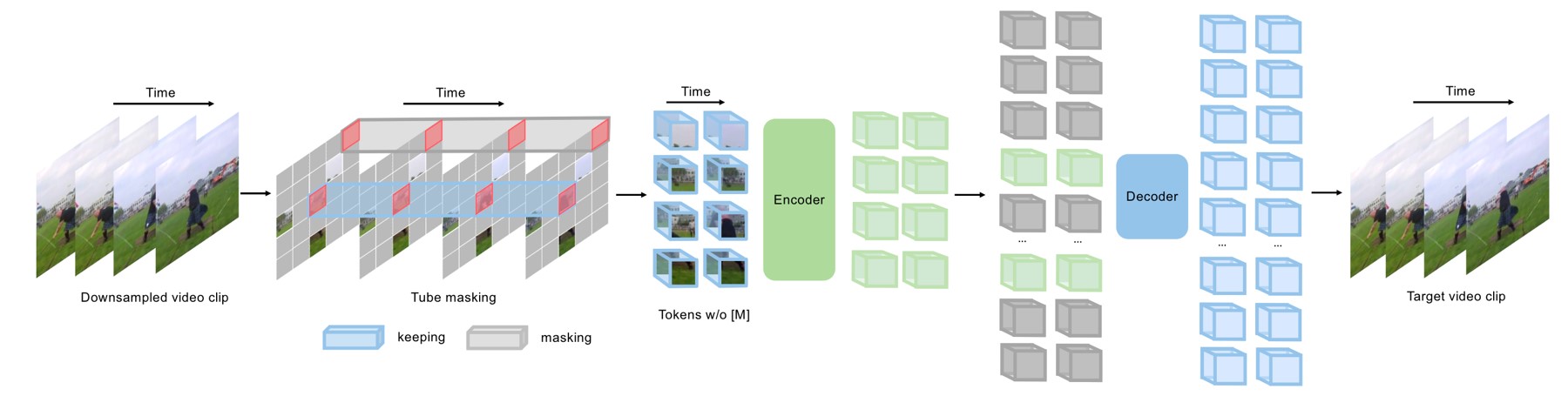
Fig. 11. VideoMAE的结构. Adapted from [15]
如上图所示,总体的结构其实没有什么大改变,依然是通过遮盖的方式进行预训练。改变的地方主要是使用了3D的cube而不是2D的patch作为token。
实验结果
作者在Something-Something-V2[16]上进行了实验,如下图所示: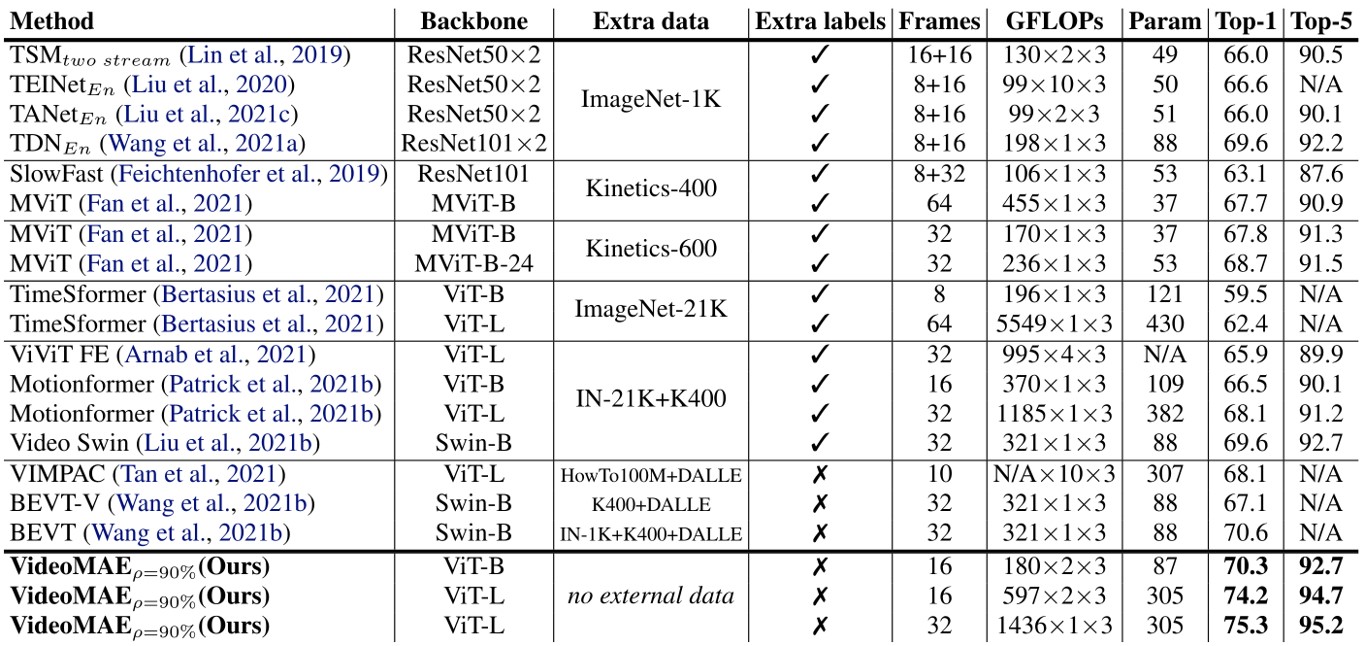
Fig. 12. VideoMAE在Something-Something-V2上的实验结果. Adapted from [15]
可以看到效果还是不错的。作者在文章中提到,为了训练这个模型,他们使用了64个V100。
他们也讨论了最佳的遮盖方法,认为是tube masking是最好的,即在空间维度上进行遮盖,而时间维度上保持一致。
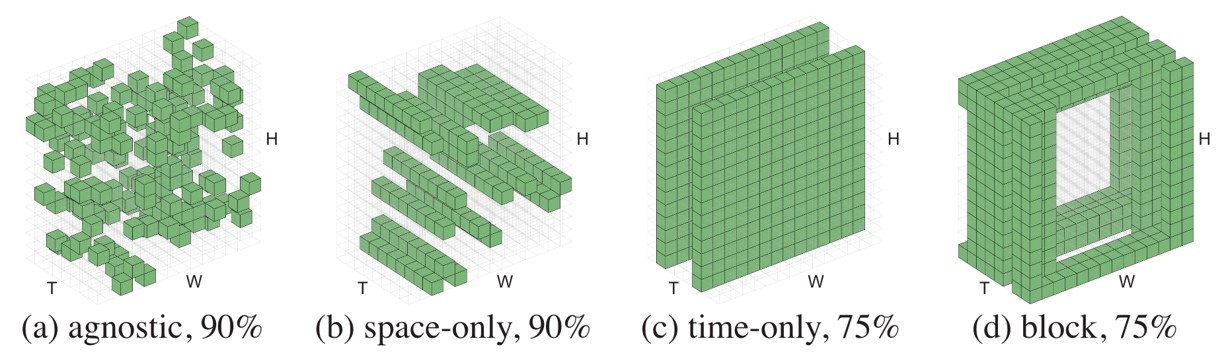
Fig. 13. 不同遮盖策略可视化. Adapted from [17]
有趣的是,另一篇论文MAE-ST[17],也是在NeurIPS 2022上发表的,也是将MAE扩展到视频上。而且方法和结构都非常类似,但是他们认为最佳的遮盖方法是随机遮盖。
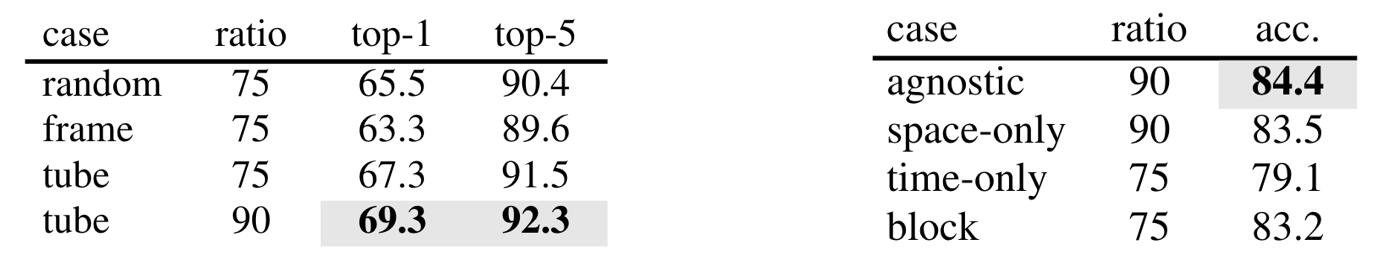
Fig. 14. 两篇论文关于不同遮盖策略的实验结果,左边来自于VideoMAE,右边是MAE-ST. Adapted from [15][17]
VideoMAE的作者认为,使用tube masking可以避免信息在时间维度上的泄露。这个泄露导致编码器看到了本来被遮盖的信息,导致性能受到影响。而MAE-ST的作者认为纯粹的随机遮盖可以防止模型对信息产生bias,从而提高了性能。
个人认为VideoMAE使用的数据集要小于MAE-ST所使用的,所以可能是数据集规模的区别导致了不同的结论。
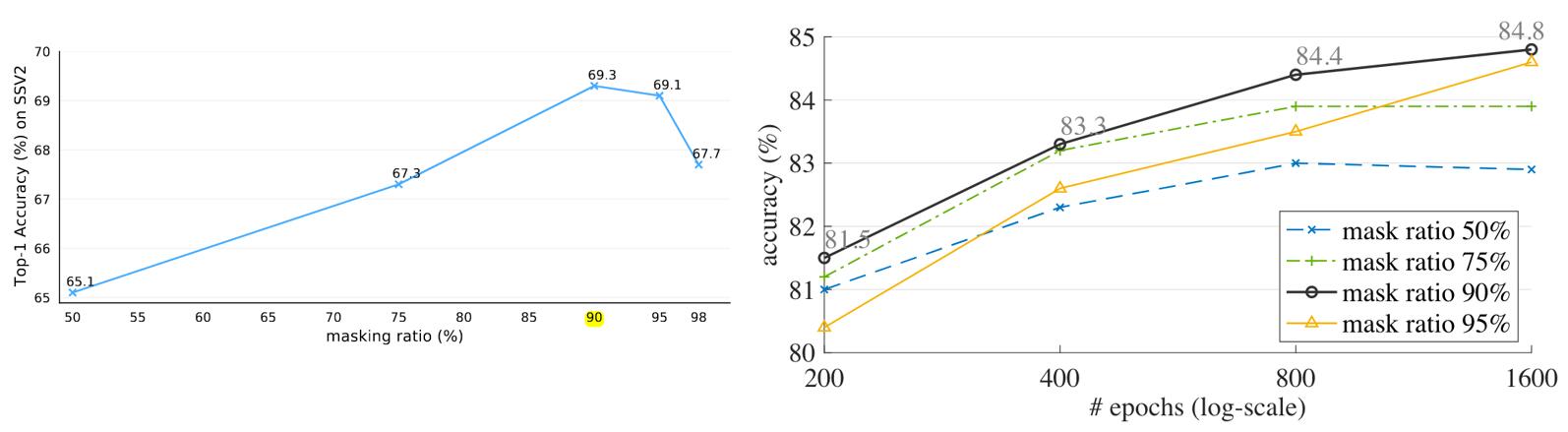
Fig. 15. 两篇论文在不同遮盖比例下的实验结果,左边来自于VideoMAE,右边是MAE-ST. Adapted from [15][17]
而关于遮盖的比例,两篇论文都认为90%是最好的。
总结
本文探讨了表征学习在深度学习中的重要性,并且介绍了MAE作为目前比较前沿的表征学习方法。MAE的核心思想是通过遮盖的方式,让模型学习到更多的信息,并且后来社区将其扩展到了视频领域。通过使用这些预训练的模型,普通的开发者也可以使用更少的数据和计算资源,将这些模型迁移到自己的任务上,从而获得更好的效果。
参考文献
- [1] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16000–16009.
- [2] A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Neural Information Processing Systems, vol. 25, pp. 1097–1105, Jan. 2012, doi: 10.1145/3065386.
- [3] S. Negi, “GPT-3: A new step towards general Artificial Intelligence,” Medium, Oct. 20, 2020. https://medium.com/@messisahil7/gpt-3-a-new-step-towards-general-artificial-intelligence-66879e1c4a44
- [4] T. Baltrušaitis, P. Robinson, and L.-P. Morency, “OpenFace: An open source facial behavior analysis toolkit,” in 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA: IEEE, Mar. 2016, pp. 1–10. doi: 10.1109/WACV.2016.7477553.
- [5] B. D. Lucas and T. Kanade, “An iterative image registration technique with an application to stereo vision,” in Proceedings of the 7th international joint conference on Artificial intelligence, in IJCAI’81, vol. 2. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., Aug. 1981, pp. 674–679.
- [6] S. Zhao, L. Zhao, Z. Zhang, E. Zhou, and D. Metaxas, “Global Matching With Overlapping Attention for Optical Flow Estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17592–17601.
- [7] A. Ranjan, D. T. Hoffmann, D. Tzionas, S. Tang, J. Romero, and M. J. Black, “Learning Multi-human Optical Flow,” Int J Comput Vis, vol. 128, no. 4, pp. 873–890, Apr. 2020, doi: 10.1007/s11263-019-01279-w.
- [8] “librosa.feature.mfcc — librosa 0.8.0 documentation,” librosa.org, 2023. https://librosa.org/doc/main/generated/librosa.feature.mfcc.html
- [9] A. Hannun et al., “Deep Speech: Scaling up end-to-end speech recognition.” arXiv, Dec. 19, 2014. doi: 10.48550/arXiv.1412.5567.
- [10] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” in 1st International Conference on Learning Representations, ICLR 2013, Workshop Track Proceedings, Y. Bengio and Y. LeCun, Eds., Scottsdale, Arizona, USA, 2013. doi: 10.48550/arXiv.1301.3781.
- [11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186. doi: 10.18653/v1/N19-1423.
- [12] “🤗 Transformers,” huggingface.co, 2023. https://huggingface.co/docs/transformers/index
- [13] Y. Bengio, A. Courville, and P. Vincent, “Representation Learning: A Review and New Perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, Aug. 2013, doi: 10.1109/TPAMI.2013.50.
- [14] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in International Conference on Learning Representations, 2021.
- [15] Z. Tong, Y. Song, J. Wang, and L. Wang, “VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training,” in Advances in Neural Information Processing Systems, Oct. 2022.
- [16] R. Goyal et al., “The ‘Something Something’ Video Database for Learning and Evaluating Visual Common Sense,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5842–5850.
- [17] C. Feichtenhofer, haoqi fan, Y. Li, and K. He, “Masked autoencoders as spatiotemporal learners,” in Advances in neural information processing systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., Curran Associates, Inc., 2022, pp. 35946–35958.