






深度学习中最一开始的Transformer是2017年推出的,非常强力[1]。可能当时作者觉得这个东西很强,所以才会赋予”变形金刚”的名字吧。而后来,Transformer也广泛的推广到了计算机视觉(CV)领域,从2020年开始,就有对Transformer在CV中的大量新研究发表。
本文主要会讲最初的Transformer,Vision Transformer(ViT)和Multi-scale Vision Transformer(MViT)。
最初的Transformer
解决并行问题
最初的Transformer是来源于这篇,”Attention is all you need”,用于自然语言处理(NLP)的机器翻译任务的。以前的RNN(包括LSTM[2], GRU[3])层计算并不能并行,因为一个序列中的某一个元素的计算是要基于别的元素的。如下图所示。
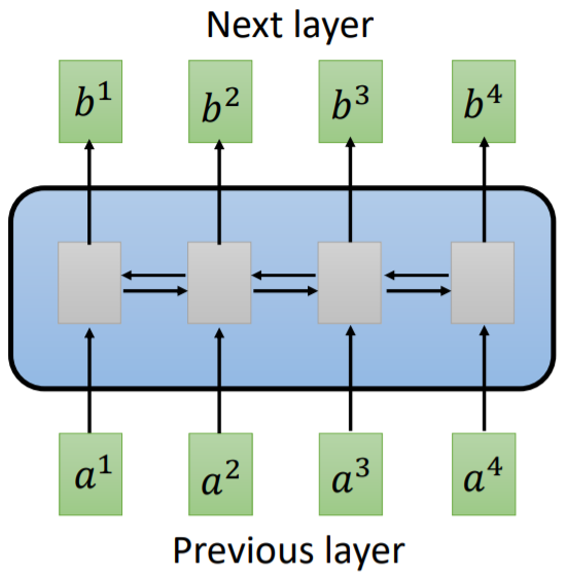
Fig. 1. RNN layer. Adapted from [4]
其中$a^1$到$a^4$都是一个序列中的token,RNN层可以看到一个序列中的全部信息,包括位置信息。但是这里每一个token的计算需要其他token的计算结果,所以无法做到并行化提高效率。
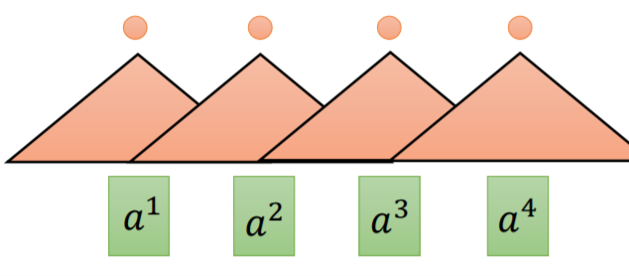
Fig. 2. Convolutional layer. Adapted from [4]
如上图所示, 使用卷积层[5]虽然可以并行计算,但是覆盖面积受到卷积核(kernel)的限制,无法在距离比较远的token中提取特征。
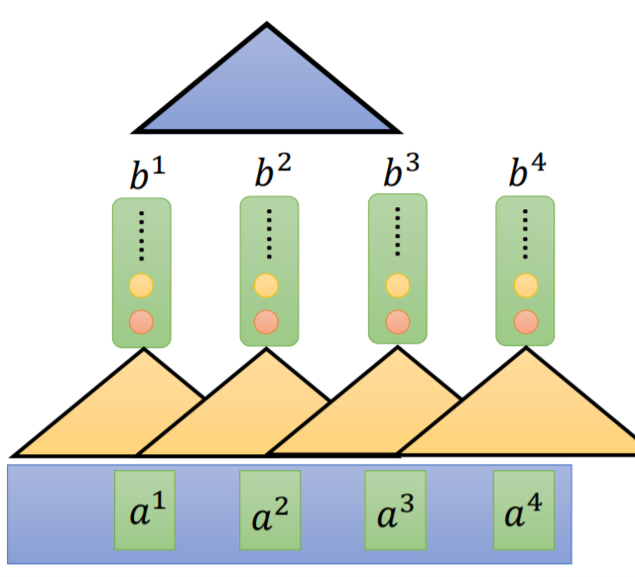
Fig. 3. Stacked convolutional layer. Adapted from [4]
如上图所示,很多人会通过将卷积层堆叠起来以达到提取更多特征的目的,但是这个覆盖范围其实依然并不是很宽,而且也需要更多的计算。
我们需要的是一个有长时记忆,并且可以并行处理的结构。所以这篇论文提出了Self-attention机制和Multi-Head Attention Layer。
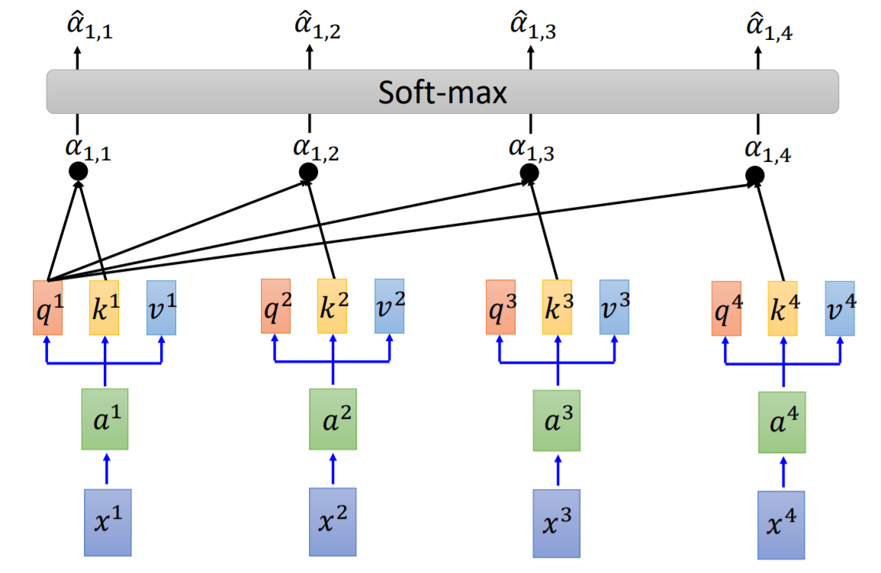
Fig. 4. Calculation of $K^i$ and $Q^i$ in self-attention layer. Adapted from [4]
首先,我们有一个输入序列,从$x^1$到$x^4$。在Embedding之后,会将每一个token转换成1-D vector,$a^1$到$a^4$。使用3个线性层分别对应Q,K,V的权重,则可以把$z^i$转换成Q (Query),K (Key),V (Value)的向量。这个计算方式如下所示。
$$
\begin{split}
q^i &= W^qa^i \\
k^i &= W^ka^i \\
v^i &= W^va^i
\end{split}
$$
我们以第一个token作为例子,需要用$q^1$与所有token的$k$相乘,从而求得$\alpha_{1,1}$到$\alpha_{1,4}$。之后,通过一个softmax进行标准化使得它们的和为1,得到$\hat{\alpha}_{1,1}$到$\hat{\alpha}_{1,4}$。
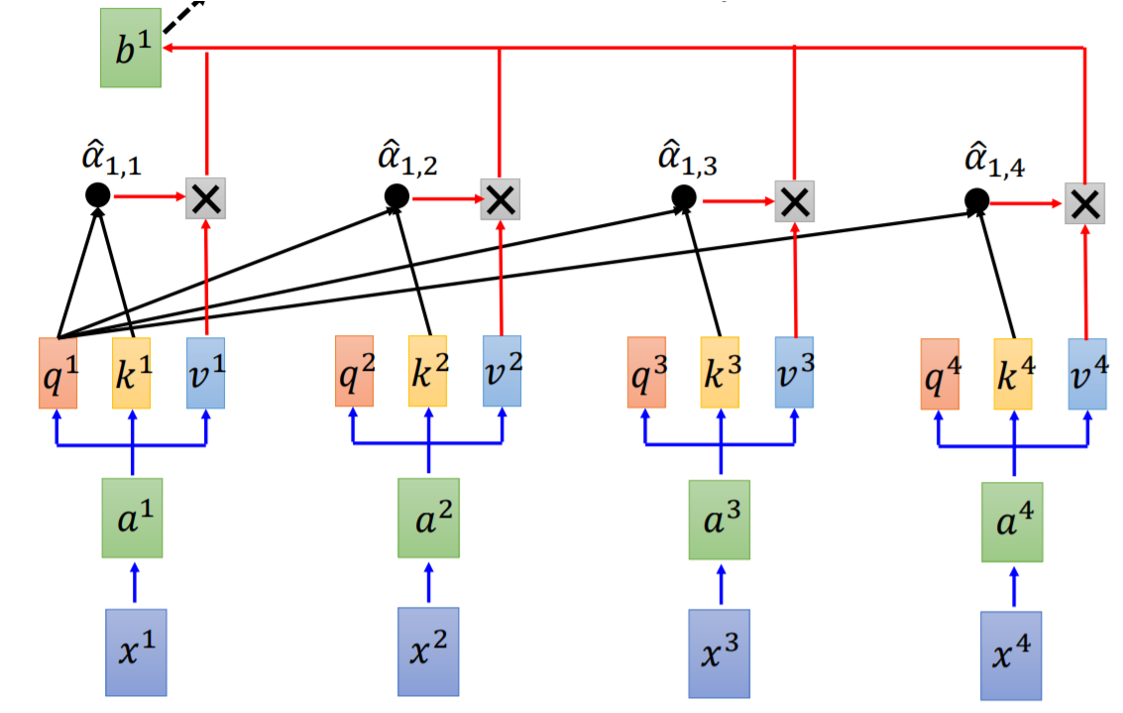
Fig. 5. Calculation of $b^i$ in self-attention layer. Adapted from [4]
然后,再对计算出来的$\hat{\alpha}_{1,1}$到$\hat{\alpha}_{1,4}$和$v$相乘求和。以第一个token为例,它的attention层输出是,
$$
b^1 = \sum_i\hat{\alpha}_{1,i}v^i
$$
重复同样的步骤,则可以得到$b_1$到$b_4$。以上的步骤看起来计算相当的复杂,但是其实可以通过几个比较简单的矩阵运算即可完成,所以它是可以很容易通过GPU进行并行计算的。
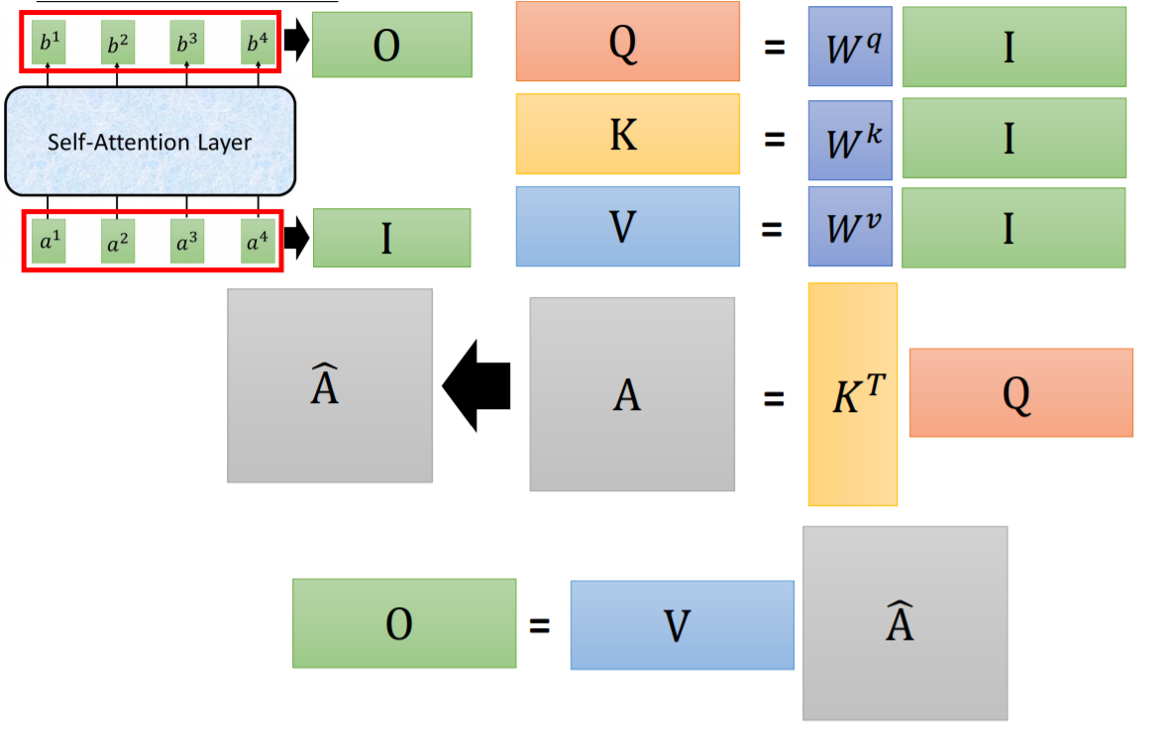
Fig. 6. Matrix multiplication form in self-attention layer. Adapted from [4]
左上角的$O$代表output,$I$代表input。而这个$I$则是将所有的输入$a_i$叠起来变成一个2D矩阵。而以上的全部需要一个一个迭代计算的过程都可以用矩阵乘法的方式实现,总的计算其实很方便。正因为这个容易进行并行计算,所以在运算速度上是快于RNN的。
Transformer结构
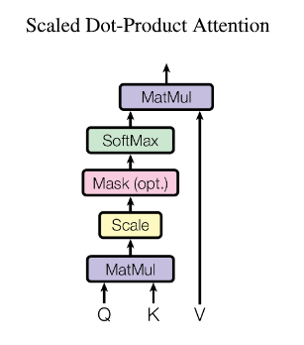
Fig. 7. Scaled dot product attention. Adapted from [1]
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_K}})V$$
如上所示[1],这个过程被称为Scaled Dot-Product Attention。你会注意到这个公式里除以一个$\sqrt{d_K}$。根据原文的说明,这个的目的是为了把值重新缩放回 Mean = 0, Variance = 1 的状态。
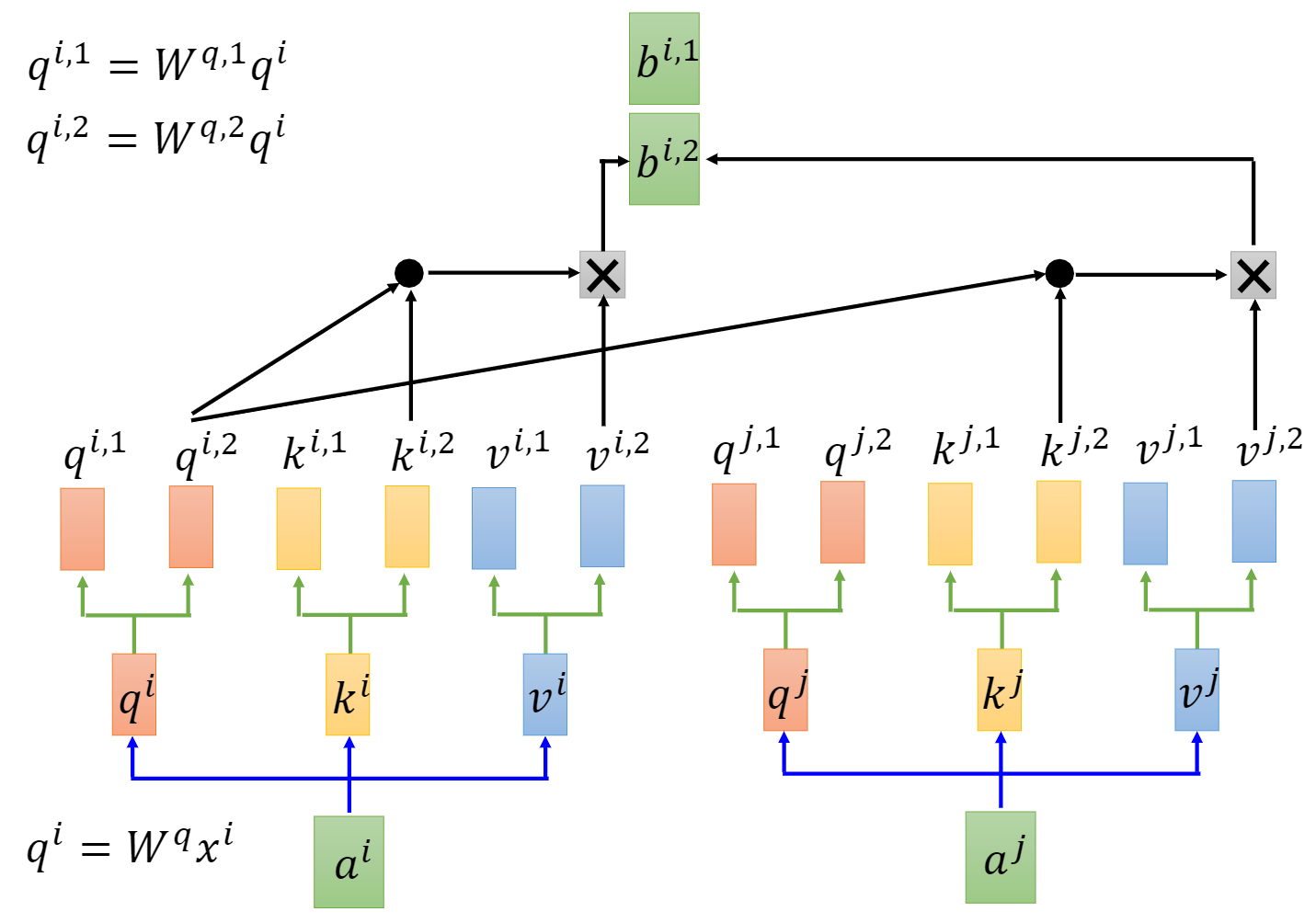
Fig. 8. Multi-head attention. Adapted from [4]
除此之外,他们还提出了一个Multi-Head Attention Layer,相比于普通的attention层,这个多头attention层有多个attention层互相并行。最后把多个并行的attention层拼接,再通过一个全连接层进行映射,把维度保持在和输入相同的状态。
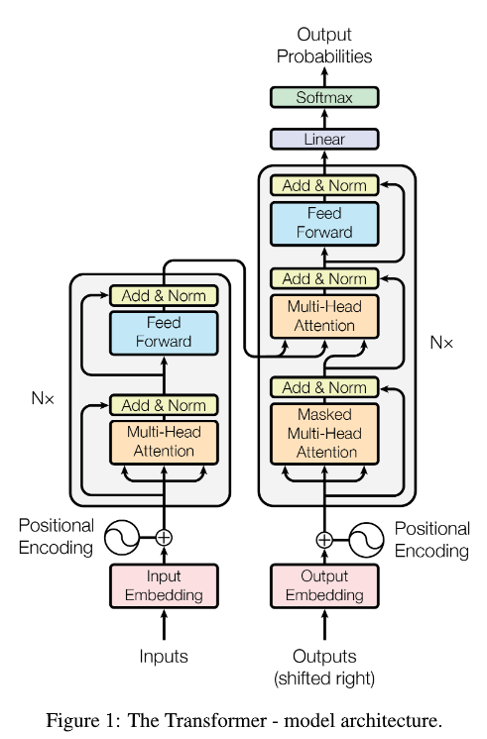
Fig. 9. Transformer structure. Adapted from [1]
如上图所示,整个Transformer是一个encoder-decoder结构。如果这个Transformer的任务是把英文翻译成中文,那在encoder的inputs这里输入中文句子,在decoder的输入端输入英文句子,decoder的输出则是概率。从encoder开始,输入的token序列会先送入embedding层转换成向量,然后再和positional encoding相加。因为在attention层中输入token并不会知道其中的位置信息,所以需要加一个positional encoding。因为矩阵相加可以视为拼接的一种特殊情况,所以通过embedding和positional encoding相加,attention层可以同时获取两者的信息,提取的特征更有效率。这个positional encoding可以是自己手动设定的,也可以是通过学习的。在这篇文章下用的是手动设定的。相加之后,会有4条路线,1条是类似于ResNet[6]的恒等连接,而另外3条则是通过对应的全连接层得到Q,K,V,再输入进attention层。在结束了multi-head attention层的计算之后,接下来是一个Add & Norm层,这个层的过程就是将attention层的输入和输出相加,并且做一个layer normalization(LN)[7]。
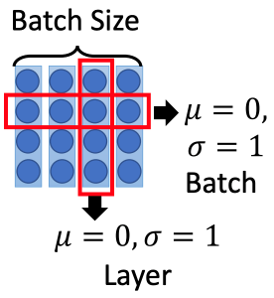
Fig. 10. Layer normalization. Adapted from [4]
如上图所示[4],和常用的batch normalization(BN)[8]相比,主要是标准化的维度不同。LN是在一个输入中跨通道的标准化,BN是在一个batch中跨数据但是在同一个通道下进行标准化。在sequence数据中,一般使用LN而不是BN。
然后是decoder部分,这里的decoder的输入,也就是机器翻译的结果是需要右移一位的(shifted right),因为第一位是<BOS>标签,作为一个句子的开头。对比encoder和decoder,主要区别在于decoder的第一层是一个Masked Multi-Head Attention。因为对于一个基于时间序列的预测来说,当然是不能通过未来的信息去预测的,所以在这个Masked Multi-Head Attention层中,所有的token输入只能看到前面的信息,而后面的信息都会被隐藏。
在这个Masked Multi-Head Attention层之后,会有一个普通的Multi-Head Attention,但是其中的Q和K是来源于encoder计算的结果,只有V是来自于上一层的输出。个人理解是Q和K可以寻找不同token在这个sequence之间的相关性,所以encoder的输出要拿来给decoder使用。
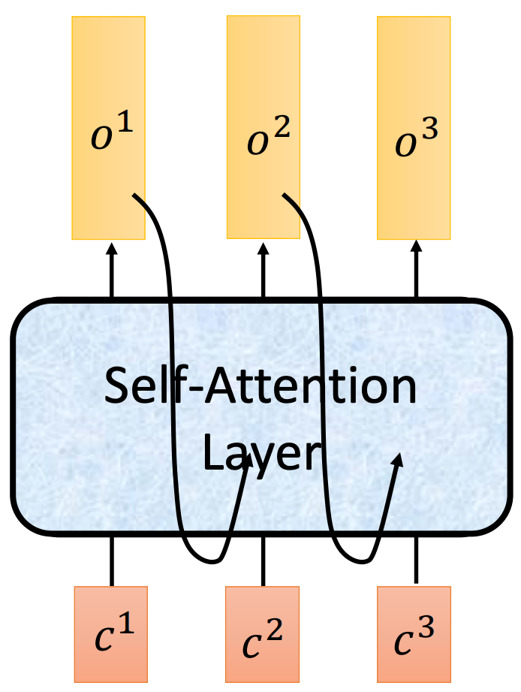
Fig. 11. Transformer inference. Adapted from [4]
如上图所示[4],在预测的时候,因为不知道翻译的结果,所以只能一个一个预测,将第一个预测出的词放到这个序列的第二个输入才能依次预测出整个句子。在训练的时候因为知道了全部内容,所以可以并行,但是在预测中是不行的。
尝试把Transformer用于CV
在Transformer发布之后,有很多研究在尝试把Transformer结果用于CV。
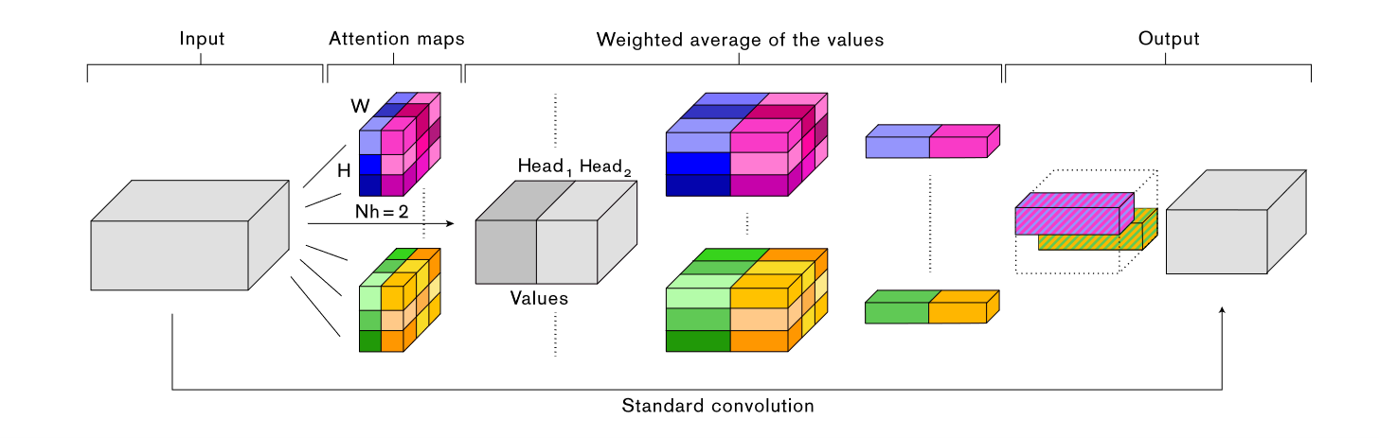
Fig. 12. Attention augmented convolutional network. Adapted from [9]
比如这一篇[9],同时使用传统的卷积和新的Self-Attention机制用于计算机视觉相关的任务。
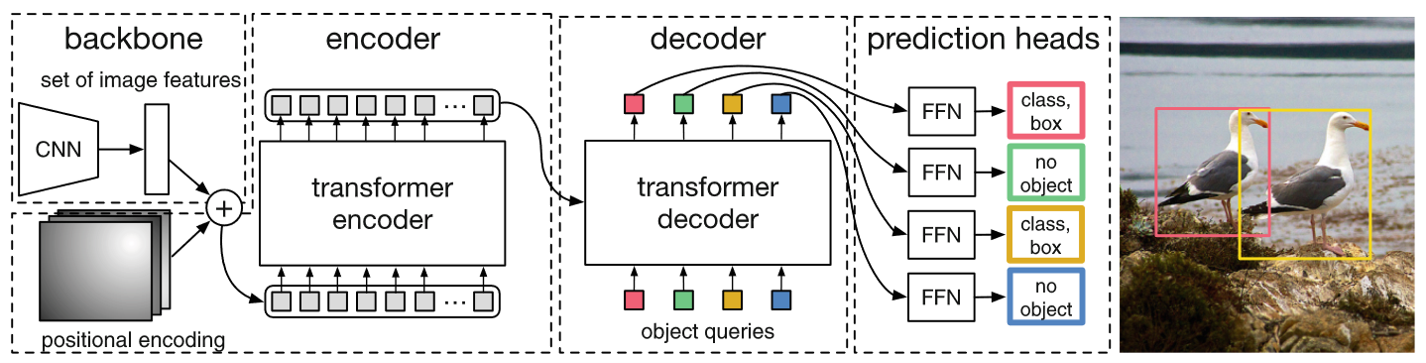
Fig. 13. Object detection transformer. Adapted from [10]
而这一篇[10],则仅仅用CNN替代原始Transformer中的Embedding过程,剩下的都与原版[1]很像。同样是完整的Transformer encoder和decoder,还有positional encoding,最后生成的结果也是一个个box用于对象检测(object detection)。这个过程已经和原版很像了。
关于这两篇的详解,已经在续篇中详细介绍。
Vision Transformer
之前的研究很少有讲Transformer直接用在CV上的,而且用上了速度也很慢。在2020年年底,有一篇论文,”An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”,提出了Vision Transformer (ViT)[11],提供了另一种方法让本来用于NLP的Transformer可以直接用在CV上。在ViT中,每一个Transformer的token其实是一个图片的patch,这也是标题这么起的原因。在这篇论文中,这个ViT主要是用于最基础的图像分类任务。
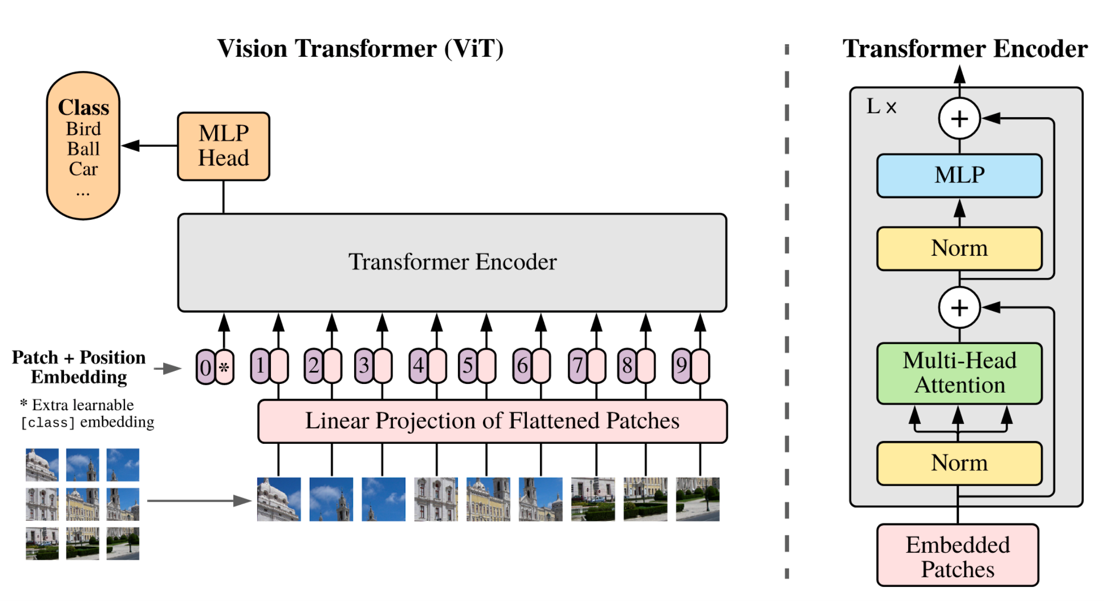
Fig. 14. Vision transformer. Adapted from [11]
具体步骤
一开始我们有一个图片$x$,高度$H$,宽度$W$,通道数$C$。对于RGB图像来说$C=3$。
$$x\in H\times W\times C$$
正如之前所说,我们先需要讲这个图片分成一块一块patch,然后将一个patch中的所有数值全部暴力的压扁到一维向量。假设patch都是正方形,边长为$P$,一个图片中的patch数量为$N$。则,
$$x_p\in N \times (P^{2}C)$$
其中,
$$N=\frac{HW}{P^2}$$
所以我们是将一个patch本来为三维矩阵$(P\times P \times C)$直接摊平为一维向量,长度为$P^{2}C$。而因为有$N$个patch,所以最后的结果是$N \times (P^{2}C)$的二维矩阵。这个形状是符合Transformer输入的。
然而$P^{2}C$的长度可能太长了,于是我们可以使用一个线性映射将维度降低到$N\times D$,其中$D$是新的patch向量的长度。把降维之后的矩阵记为$z_p$。
$$z_p\in N\times D$$
然后,我们需要增加一个可训练的token,$z_{class}$,放到整个$Z$的第一位,并且加上一个可训练的positional encoding。
$$Z=[z_{class},z_p^1,z_p^2,z_p^3,\cdots,z_p^N]+E_{pos}$$
由这些新的向量组成的矩阵加上positional encoding $E_{pos}$,得到的结果的矩阵记为$Z$。
这些东西就可以直接放进一个Transformer encoder,得到的结果也是一个sequence,但是只取第一个,也就是$z_{class}$对应的输出。将这个向量放入一个MLP用于分类,得到分类结果$\hat{y}$,与label $y$一起计算loss并反向传播训练整个ViT。
Class Token
根据原文,这个是从BERT[12]的结果中拿过来的,因为使用一个可训练的token,会比使用别的token的结果用于分类更加公平,因为不会受到原先包含信息的影响。
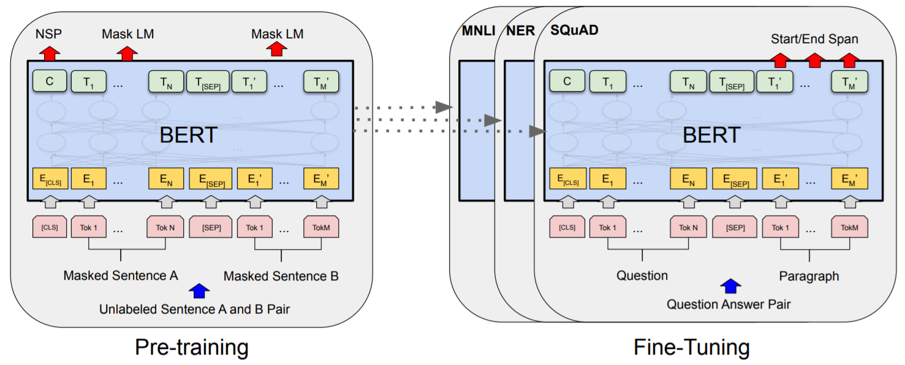
Fig. 15. BERT. Adapted from [12]
Positional Encoding
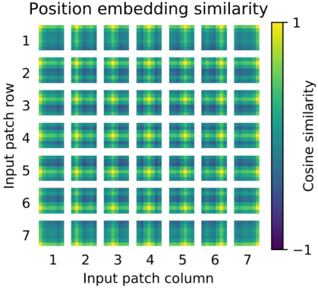
Fig. 16. Positional encoding in ViT. Adapted from [11]
然后是关于positional encoding的。这张图展示了positional encoding的相似度,越亮说明越相似。我们可以看到,对于每一个patch,在相似行和列的patch的相似度是较高的,而那些距离比较远的相似度则较低。这说明一个可训练的positional encoding是可以学到其中的位置关系的。
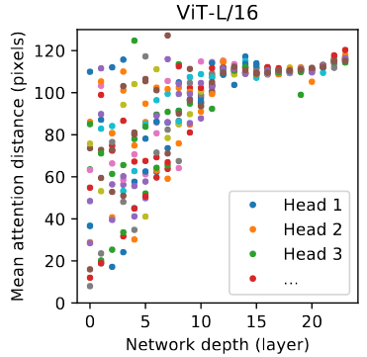
Fig. 17. Attention distance. Adapted from [11]
这张图展示了attention距离和网络深度的关系。x轴是网络深度,y轴是平均attention的patch之间的距离,不同的点代表不同的head找到的attention。很显然,在网络很浅的时候,attention层依然能找到距离较远的关系。如果这是一个CNN网络,那这个结果就应该会分布在这张图中一堆散点的下边缘。所以不用特别深的网络,ViT依然能学到这张图的全局特征。
Multiscale Vision Transformer
在之前的ViT[11]中,实际上每一个attention层的输入输出维度都是一样的,所以attention层只是在一个scale上进行检测。这篇2021年的论文提出了Multiscale Vision Transformer (MViT)[13]。大家都知道,在CNN中经过了数层卷积层之后会有一个降采样层降低特征图的长宽,这样之后的卷积层将能提取到不同scale的特征。这篇论文想通过同样的方式来把这个multi-scale的想法用在ViT上。
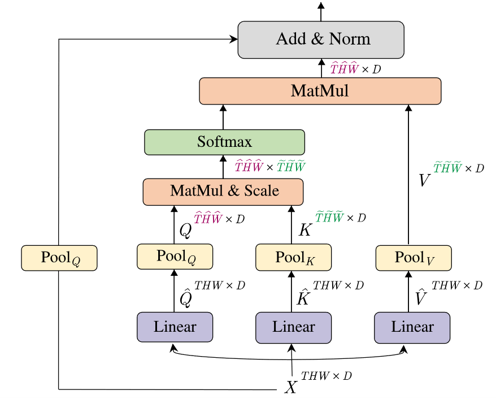
Fig. 18. Multiscale vision transformer. Adapted from [13]
如上图所示[13],他们提出了Multi-Head Pooling Attention (MHPA)层。很显然,最大的区别就在于对于每一条路上都加了一个pooling层。在这些pooling层之后,那些向量的长度就会降低,这样后面的attention层就能检测到不同scale的特征了。
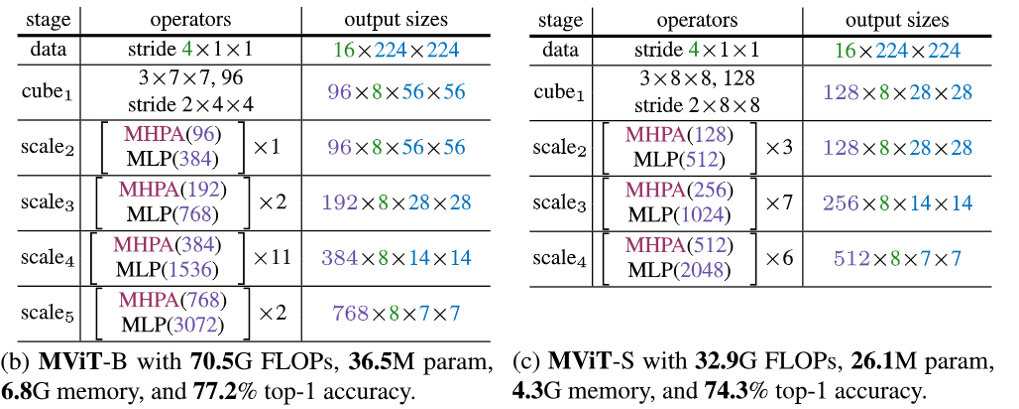
Fig. 19. MViT structures. Adapted from [13]
在这篇文章里,他们提出两个MViT的结构,分别是MViT-B和MViT-S,用于视频分析的。他们把一整个网络分成了多个stage。在第一个stage中是读取数据,因为视频是用3D矩阵表示,切分patch也是3D,所以patch在这里被成为cube。然后在后面的stage中,cube的长度和宽度都不断降低,而通道数则不断增加。在最终的实验结果中,MViT的表现要优于之前的ViT模型,而且参数数量也更少了,运行速度也更快了。
推荐一个GitHub Repository
这里推荐一个GitHub repo,叫Awesome Visual-Transformer,里面收录了许多用于CV的Transformer论文和官方实现的code链接[14]。
https://github.com/dk-liang/Awesome-Visual-Transformer
参考文献
- [1] A. Vaswani et al., “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, Dec. 2017, pp. 6000–6010.
- [2] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, Nov. 1997, doi: 10.1162/neco.1997.9.8.1735.
- [3] K. Cho et al., “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,” arXiv:1406.1078 [cs, stat], 2014.
- [4] "Transformer & BERT", Speech.ee.ntu.edu.tw, 2021.
- [5] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, ‘Gradient-based learning applied to document recognition’, Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, Nov. 1998, doi: 10.1109/5.726791.
- [6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [7] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer Normalization,” arXiv:1607.06450 [cs, stat], 2016.
- [8] S. Ioffe and C. Szegedy, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,” in International Conference on Machine Learning, Jun. 2015, pp. 448–456.
- [9] I. Bello, B. Zoph, A. Vaswani, J. Shlens, and Q. V. Le, “Attention Augmented Convolutional Networks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 3286–3295.
- [10] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-End Object Detection with Transformers,” in Computer Vision – ECCV 2020, Cham, 2020, pp. 213–229, doi: 10.1007/978-3-030-58452-8_13.
- [11] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” arXiv:2010.11929 [cs], Oct. 2020.
- [12] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, Jun. 2019, pp. 4171–4186, doi: 10.18653/v1/N19-1423.
- [13] H. Fan et al., “Multiscale Vision Transformers,” arXiv:2104.11227 [cs], Apr. 2021.
- [14] "dk-liang/Awesome-Visual-Transformer", GitHub, 2021. [Online]. Available: https://github.com/dk-liang/Awesome-Visual-Transformer.