







人生苦短,我用Python![1]
这个系列是一个帮助零基础的人入门编程的教程,本文主要介绍Python中包和库的概念,还有一些常用的标准库和第三方库。
包和模块
Python可以通过导入(import)关键字使用来自于外部的代码。在Python中,包(package)基本上是可以视为一系列模块(module)组成的目录。而在第五章提到,模块是一个包含了定义和语句的Python源代码文件。
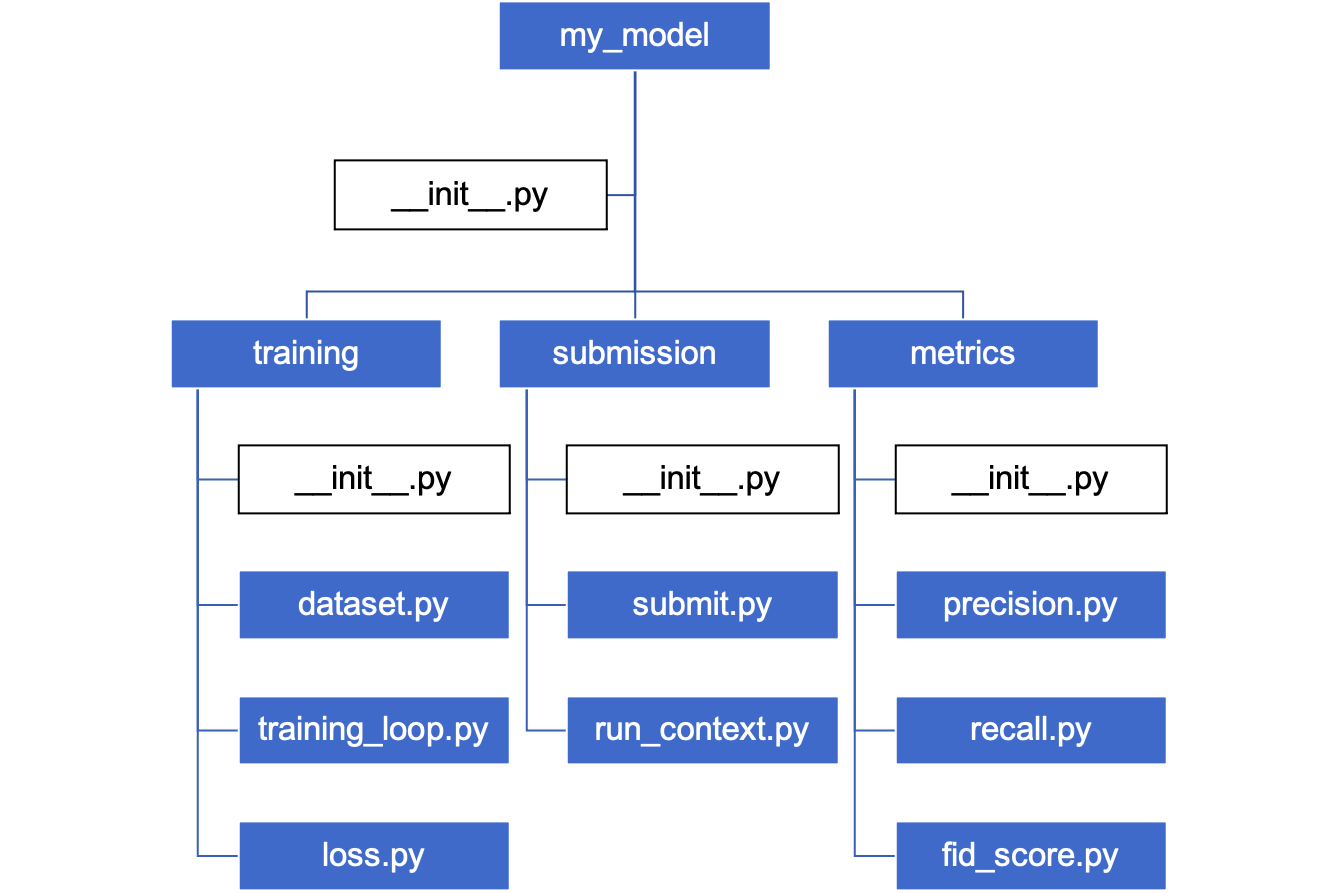
Fig. 1. 一个Python的包和模块的例子。Adapted from [2]
这张图展示了一个例子,这里的my_model,training,submission和metrics都是文件夹,而剩下.py结尾的都是文件。根据以上定义,我们可以认为,刚才提到的4个文件夹是4个包,而training,submission和metrics是my_model包的子包。而在各个包之下,剩下的Python文件,比如说dataset.py,training_loop.py都是模块。每一个包下都需要一个__init__.py来定义这个包的入口,可以是空白文件。
如果我们想导入training包中的dataset模块中的load_dataset函数,可以这样写:
1 | import my_model.training.dataset.load_dataset |
当然,这样的写法很长,看起来很不方便,所以我们需要from关键字。
1 | from my_model.training.dataset import load_dataset |
通过这样的方法可以较为简洁的导入外部代码。
另外,可以通过以下写法导入指定模组的全部成员,但是不推荐使用。
1 | from my_model.training.dataset import * |
相对导入
除了从绝对路径导入之外,我们也可以通过相对路径进行导入。
如果在编辑my_model/submission/submit.py,想要导入my_model/metrics/precision.py中的Precision类,可以这样写:
1 | # absolute path |
在运行环境相对复杂时,使用相对导入更加合适。
库和框架
库(library)一般而言是指可以重用的代码,经常和包(package)混用。但是一般来说,包是模块的集合,而库是包的集合。
标准库是Python官方提供的库,在安装了Python之后,即可直接导入使用。
比如说,
- 用于文字处理
string,re,difflib- 用于数学计算
math,ramdom,statistics- 用于函数式编程
itertools,functools,operator- 用于文件访问
os,shutil,pathlib- 用于文件压缩和解压
zlib,gzip- 用于操作系统服务
os,io,time,subprocess- 用于并行计算
multiprocessing,threading,concurrent
除了标准库之外,还有其他开发者提供的第三方库。这些库数量繁多,功能强大,也正是因为这些库和这个社区才让Python成为强大的编程语言。
为什么标准库需要导入
如果标准库已经是Python自带的了,为什么还需要额外导入?一个原因是,显式的声明要比隐式更好,通过指定导入哪些库,可以更好的解释这个代码的目标。
另一个原因是Python导入标准库的时候,会运行它们。如果每次运行Python代码都要导入全部的标准库,那会显著的增加Python程序的运行时间,即使它只是一行print("hello world")。
第三个原因是只有有限数量的名字可以给函数,如果同时导入每个库,可能会导致名称冲突。比如说,print是被多个标准库使用的通用名字,random和string也是一样。这种想法被成为命名空间(name space)。
标准库
在这一节,我们将会简单介绍几个常用的标准库。
math
math标准库提供了一些常用的数学函数,主要是在不使用更加复杂的第三方库的情况下可以直接使用。
其中包括了一些函数,
- 求幂和对数
exp(x),log(x, base),pow(x, y), …
- 三角函数
sin(x),cos(x),tan(x), …
还有数学常量,
pi,e,inf,nan
random
random标准库提供了创建假随机数(pesudo-random number)的方法。
最基础的函数: random()
- 返回一个随机浮点数,它在[0, 1)之间。
随机的整数: randint(a, b)
- 返回一个随机整数,它在[a, b]之间。
为序列准备的随机数函数:
choice(seq): 返回序列中的一个随机元素。shuffle(seq): 打乱序列中的元素。sample(seq, k): 从序列中随机获取k个元素。
第三方库
Python的第三方库是外部开发者提供的,所以并不会预先和Python一起安装。所以在使用第三方库之前,我们需要先安装它。
其中最简单的方式是使用pip命令。举个例子,如果需要安装NumPy这个库,
1 | pip install numpy |
在使用pip命令的时候,将会自动的从PyPI上下载安装包。PyPI是一个Python官方提供的第三方库的平台[5]。基本上任何一个第三方库都会介绍安装这个库的方法。
除此之外,如果使用了Anaconda[6]或者Miniconda[7]来安装Python的话,也可以使用conda命令来安装第三方库。
1 | conda install numpy |
NumPy
NumPy是一个用C编写的数学计算第三方库[8]。很多其他优秀的第三方库都是基于NumPy来实现的,比如说SciPy[9], pandas[10]。
使用NumPy的时候,我们通常会使用import numpy as np的方式来导入。
NumPy的核心是提供了一个新的数据结构: ndarray(多维数组)。
- 1D数组:
np.array([1, 2, 3]) - 2D数组:
np.array([[1, 2, 3], [4, 5, 6]])
类似于Matlab[11]和R[12]中的数组,一切都可以向量化(vectorize)。
1 | import numpy as np |
利用向量化进行编程,可以极大的提升运行的效率,弥补Python的速度短板。
关于NumPy的更多使用方法,请参考官网。
SciPy
SciPy是一个NumPy的扩展包[9],提供了很多用于科学计算的算法,其中包括
- 线性代数
- 微积分
- 统计分布
- 优化
- 聚类
- 图像处理
- 信号处理
使用SciPy的时候,我们通常会使用import scipy as sp的方式来导入。
关于SciPy的具体用法,请参考官网。
Matplotlib
Matplotlib是一个Python的2D/3D绘图库[13],主要用于数据可视化,其中包括直方图,柱状图,散点图,等等。
其中提供了一个用于快速绘图的包pyplot
- 一些常用的函数:
plot(),hist(),scatter(),show()
使用Matplotlib的时候,我们通常会使用import matplotlib.pyplot as plt的方式来导入。
关于Matplotlib的具体用法,请参考官网。
pandas
pandas是一个用于结构化数据处理和分析的Python库[10]。
常用的导入方法是import pandas as pd。
它提供了一个2维数据结构DataFrame,类似于一个表格。
从dict创建:
1 | a_dataframe = pd.DataFrame({ |
从NumPy的ndarray创建:
1 | a_dataframe = pd.DataFrame( |
一些学习pandas的好资料:
- pandas官方文档[14]: https://pandas.pydata.org/pandas-docs/stable/
- 10分钟学习pandas[15]: https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
- pandas备忘录[16]: https://github.com/pandas-dev/pandas/blob/main/doc/cheatsheet/Pandas_Cheat_Sheet.pdf

Fig. 2. pandas 备忘录。Adapted from [16]
实践试试
在这次的课后实践中,我们将会尝试介绍一些第三方库。
可视化数学函数
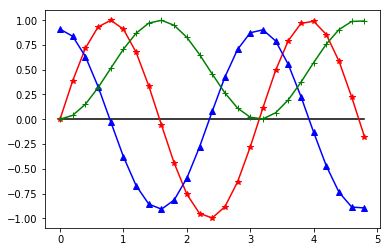
在这一部分中,我们需要使用NumPy, SciPy和Matplotlib来可视化一些数学函数。
在这么短的一篇教程中想要覆盖这三个庞大的第三方库有些太难了,我们先从简单的地方开始,可以介绍一些这些库到底是干什么的。如果简单说的话:NumPy作为数据结构的主要来源;SciPy和pandas的存在是为了便于进行复杂的科学计算;Matplotlib用于可视化。
1 | import numpy as np |
运行结果:
数据处理
现在让我们试试看pandas。这个库提供了格式化输出的方法,但是能做到的远远不止这些,包括填充数据中的缺失值,或者处理NaN。我们可以试试看以下的部分。
首先,从上个部分中导入f1,f2和f3生成的数值,保存在pd.DataFrame中,并且通过DataFrame.describe展示统计数据。
1 | import pandas as pd |
1 | f1 f2 f3 |
找出每一列中的最大值。
1 | # max values of f1, f2, and f3 |
1 | f1 f2 f3 |
根据列f2进行重排序。
1 | df.sort_values(by='f2') |
参考文献
- [1] B. Eckel, “sebsauvage.net - Python”, Sebsauvage.net, 2021. [Online]. Available: http://sebsauvage.net/python/.
- [2] "Difference Between Python Modules, Packages, Libraries, and Frameworks", LearnPython.com, 2022. [Online]. Available: https://learnpython.com/blog/python-modules-packages-libraries-frameworks/.
- [3] "math — Mathematical functions — Python 3.10.4 documentation", Docs.python.org, 2022. [Online]. Available: https://docs.python.org/3/library/math.html.
- [4] "random — Generate pseudo-random numbers — Python 3.10.4 documentation", Docs.python.org, 2022. [Online]. Available: https://docs.python.org/3/library/random.html.
- [5] PyPI, 2022. [Online]. Available: https://pypi.org/.
- [6] "Anaconda | The World's Most Popular Data Science Platform", Anaconda, 2022. [Online]. Available: https://www.anaconda.com/.
- [7] "Miniconda — Conda documentation", Docs.conda.io, 2022. [Online]. Available: https://docs.conda.io/en/latest/miniconda.html.
- [8] "NumPy", Numpy.org, 2022. [Online]. Available: https://numpy.org/.
- [9] "SciPy", Scipy.org, 2022. [Online]. Available: https://scipy.org/.
- [10] "pandas - Python Data Analysis Library", Pandas.pydata.org, 2022. [Online]. Available: https://pandas.pydata.org/.
- [11] "MATLAB - MathWorks - MATLAB & Simulink", MathWorks, 2022. [Online]. Available: https://www.mathworks.com/products/matlab.html.
- [12] "R: The R Project for Statistical Computing", R-project.org, 2022. [Online]. Available: https://www.r-project.org/.
- [13] "Matplotlib — Visualization with Python", Matplotlib.org, 2022. [Online]. Available: https://matplotlib.org/.
- [14] "pandas documentation — pandas 1.4.2 documentation", Pandas.pydata.org, 2022. [Online]. Available: https://pandas.pydata.org/pandas-docs/stable/.
- [15] "10 minutes to pandas — pandas 1.4.2 documentation", Pandas.pydata.org, 2022. [Online]. Available: https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html.
- [16] "pandas/Pandas_Cheat_Sheet.pdf at main · pandas-dev/pandas", GitHub, 2022. [Online]. Available: https://github.com/pandas-dev/pandas/blob/main/doc/cheatsheet/Pandas_Cheat_Sheet.pdf.