






人生苦短,我用Python![1]
这个系列是一个帮助零基础的人入门编程的教程,本文承接上一篇,介绍Python的数据结构和集合类型。
数据类型和数据结构
Python中的数据类型可以分为两种,
- 原子类型(Atomic)
- 集合类型(Collective)
原子类型是不可分的,只表示一个值,比如说int,float和bool。
集合类型是多个数据值的集合,比如说str,list,tuple,set和dict,这些类型将在本文中介绍。
数据结构
数据结构(Data Structure)定义了数据是如何在内存中物理存储和组织的,也指明了某个集合中的单个数据值是如何访问和修改的。
数据类型和数据结构的区别:
- 数据结构是计算机科学理论中的一般术语。
- 数据类型是某个特定的编程语言中的数据结构的实现。
数据结构举例:
- 原始(Primitive)数据结构(布尔Boolean, 浮点Floating-point, 整数Integer)
- 非原始(Non-primitive)数据结构(数组Array, 列表List)
- 线性结构(栈Stack, 队列Queue)
- 非线性结构(图Graph, 树Tree, 哈希表Hashmap)
Python的集合数据类型
在Python中有非原始数据结构的实现,
- 字符串str
a = "Hello"
- 列表list
a = [1, 3, 5]
- 元组tuple
a = (6, 2)
- 集合set
a = {1, 5, 3}
- 字典dictionary
a = {"a": "b", 1: 2}
内存(Memory)是连续数据存储块的集合。Python代码运行时的数据会存储在内存中。
在内存中存的信息一般是以下两者,
一个Python对象(和它的值)
指向另一个内存地址的引用
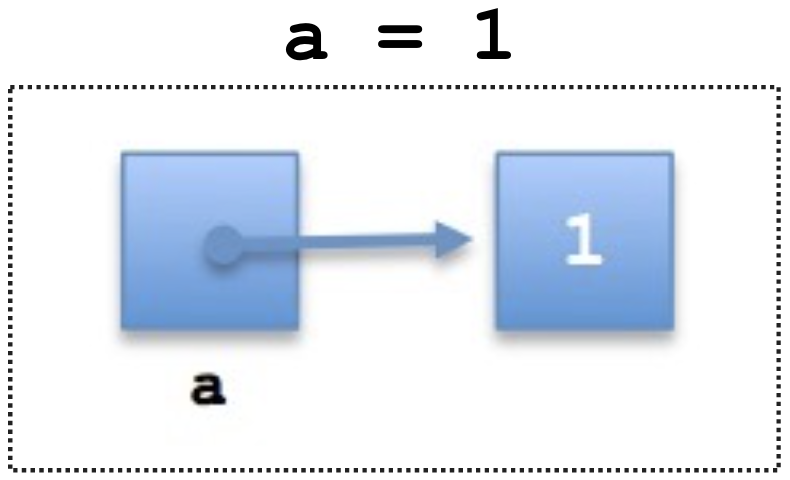
在Python中常见的str,list和tuple都是基于数组的结构。这些集合中的成员(item)是顺序的存储在一个连续的内存块上。所以在这些集合类型中,一般使用下标(index)对某个成员进行访问。
字符串
字符串(String)在Python中经常用str表示,是一个文本表示的数据类型,一个或多个字符的集合。
例: a_str = "Python"

在Python中通过index访问成员是使用中括号”a_str[index]”,其中index是从0开始。例:
- 第一个字符:
a_str[0] - 第二个字符:
a_str[1] - 最后一个字符:
a_str[len(a_str) - 1]或者a_str[-1]
字符串可以使用”+”进行拼接操作。
1 | first_name = "John" |
得到的结果是
1 | John Smith |
字符串也可以切片取一部分,通过a_str[start_index:end_index]获取从start_index(包含)到end_index(不包含)的子字符串。
如果start_index是0的话,可以省略;如果end_index是最后一位的话也可以省略。
1 | message = "Welcome to Python" |
结果是
1 | Welcome |
字符串的更多方法
1 | message = " Welcome to Python " |
一般来说比较常用的有
str.capitalize()像标题一样每个单词大写第一个字符str.count()返回这个子字符串在这个字符串中的出现次数str.endswith()返回这个字符串是否是有这个后缀str.find()查找子字符串的位置str.index()返回所给的子字符串的indexstr.isdigit()这个字符串是否全是数字str.join()将list的全部元素都合并成一个字符串str.lower()转换成小写str.replace()替换其中的某个子字符串str.split()通过某个分隔符分割成列表str.strip()去除首尾的空格
更多的字符串方法请参考Python3官方文档[2]
序列
Python中的序列(Sequence)是一个数据的集合。这些数据中的元素都可以读取,而有些序列还可以修改其中的元素。
- 列表(list), 元组(tuple), 集合(set), 字典(dict)
这些序列类型中的通用功能
- in表达式:
- 检查这个元素是不是在这个序列中
- 拼接
- 合并两个序列,一般用”+”运算符
- 通过下标取值c
- 通过一个给定的下标,取其中的一个值,在python中用中括号[]来操作
- 切片
- 通过两个下标,开始的位置和结束的位置,取一个子序列
- 一些基础分析
min,max,seq.index,seq.count等等
接下来举几个例子来看看。
in表达式
1 | if x in seq: |
拼接
1 | new_seq = seq_one + seq_two |
通过下标取值
1 | a_seq[index] # read |
切片
1 | a_seq[start_index:end_index] |
以下我们来专门看看这些具体的序列类型。
列表
列表(list)是Python中非常常用的一个类型。
- 可以保存多个任意类型的数据
- 可变的(Mutable),而且是有顺序的
创建列表的举例
- 创建空列表:
a_list = [],a_list = list() - 创建一个带有元素的列表:
a_list = [1, "two", 3.0, '4'] - 创建一个带有相同元素的列表:
a_list = [1] * 6
列表中的下标是从0开始的。
1 | fruits = ["Apple", "Mango", "Strawberry", "Banana", "Guava"] |
| index | [0] | [1] | [2] | [3] | [4] |
|---|---|---|---|---|---|
| value | “Apple” | “Mango” | “Strawberry” | “Banana” | “Guava” |
给列表添加元素:
- 添加到末端:
a_list.append(new_item) - 添加到指定位置:
a_list.insert(index, new_item)
移除元素:
- 移除末尾或者指定位置,并返回这个元素:
a_list.pop()和a_list.pop(index) - 移除指定值的元素:
a_list.remove(item)
排列元素:
- 按照值的顺序进行排列,默认升序:
a_list.sort() - 直接将元素倒序:
a_list.reverse()
一些操作列表的例子:
1 | num_list = [3, 4, 2, 6] |
用for循环搭配range进行遍历
1 | num_list = [1, 2, 3, 4, 5] |
列表推导式(list comprehension)是一个用于创建新列表的具有python特色的方法,新列表的元素都是通过某种方法从已有列表中生成。
举个例子,如果我们希望把一个列表中的奇数收集起来,做一个平方添加到新列表里。
1 | num_list = [1, 2, 3, 4, 5] |
等价于
1 | num_list = [1, 2, 3, 4, 5] |
元组
元组(tuple)是python中用于表示打包一块的多类型集合的类型。
创建元组的举例:
- 空元组:
a_tuple = () - 有一些值的元组:
a_tuple = (0, "a") - 列表转换到元组:
a_tuple = tuple([0, "a"])
读取元组中的元素:
- 使用下标:
a_tuple[0] - 解构赋值给新变量:
x, y = a_tuple
元组是不可变的,不能对其中一个元素重新赋值。
1 | coord = (0, 1) |
列表和元组主要区别:
- 列表主要代表一个有顺序的序列,而元组是表示一个结构
- 列表是可变的,元组是不可变的
- 元组比列表更节省内存
实践试试
这一节中会试试如何使用字符串和列表去给一个句子做字符统计,试试看一步一步的做下来吧。这次使用的环境和第一篇教程相同,具体内容请看Python编程基础01:Python语言和编程。
从字符串开始
这开始编程之前,可以先回忆一下字符串和列表的性质。先来给一个俳句的每一个字符串都打印出来。
1 | list_of_strings = ["This blog teaches code", "Code that will be useful soon", "Let me try this out"] |
我们也可以把多个字符串连接到一个列表中,但是依然每一句占一行。这里我们需要用\n换行符来连接字符串。
1 | # Define an empty string "haiku" |
当然我们也可以轻松把这一个长字符串重新还原成列表。
1 | print(haiku.split("\n")) |
开始使用列表
从这里开始,我们需要给上一部分定义的俳句的所有可能字符构造一个列表。我们可以用以下方式使用字符串。
1 | # Define a string of all the characters in the English alphabet |
以上只是创建这个列表的其中一个办法,有很多种办法都可以创建字母表。
接下来让我们创建26个0来作为字符计数列表的初始化。
1 | # Define a list for the count of each character in the English alphabet |
然后就开始遍历每一个字符,把计数统计上去吧。以下的代码只是一种解决方案,编程是一种艺术,就像不同的画家有不同的画风一样,可以试试看写出自己的风格。
不过请注意,以上定义的字母表是纯小写的,所以在遍历匹配的时候需要转换成小写进行匹配。
1 | # iterate each character of haiku |
结果是类似于这样
1 | a:2 |
参考文献
- [1] B. Eckel, “sebsauvage.net - Python”, Sebsauvage.net, 2021. [Online]. Available: http://sebsauvage.net/python/.
- [2] “Built-in Types — Python 3.9.1 documentation”, Docs.python.org, 2021. [Online]. Available: https://docs.python.org/3/library/stdtypes.html#string-method.